Como estava esse conteúdo?
Como o Amazon SageMaker ajuda a Widebot a realizar análises de sentimentos em árabe
As startups sabem a importância de criar ótimas experiências para os clientes. A análise de sentimentos é uma ferramenta que ajuda nisso. Ela categoriza os dados como positivos, negativos ou neutros com base em técnicas de machine learning, como análise de texto e processamento de linguagem natural (PLN). As empresas usam a análise de sentimentos para medir a satisfação dos clientes com um produto ou serviço-alvo.
A análise de sentimentos pode ser bem difícil de realizar em usuários finais árabes: as pessoas na região do Oriente Médio e do Norte da África (MENA) falam mais de 20 dialetos da língua árabe, com o árabe padrão moderno sendo o idioma mais comum.
Nesta publicação do blog, explicamos como a Widebot usa o Amazon Sagemaker para implementar um classificador de sentimentos. A Widebot é uma das principais plataformas de chatbot de inteligência artificial (IA) conversacional com foco em árabe na região MENA. Seu classificador de sentimentos é compatível com o árabe padrão moderno e o dialeto egípcio do idioma, com alta precisão quando testado em vários conjuntos de dados de diferentes domínios.
É fácil ajustar o modelo da Widebot após alimentá-lo com centenas de amostras do novo domínio ou conjunto de dados. Isso torna a solução genérica e adaptável a diferentes domínios e casos de uso.
As características de um chatbot de sucesso
Os chatbots são uma ferramenta útil para gerenciar e melhorar as experiências dos clientes, além de automatizar tarefas para que os funcionários possam se concentrar no trabalho essencial para a missão da empresa. As startups, especialmente, sabem que é importante usar serviços gerenciados para dedicar tempo às tarefas que mais importam para seu sucesso.
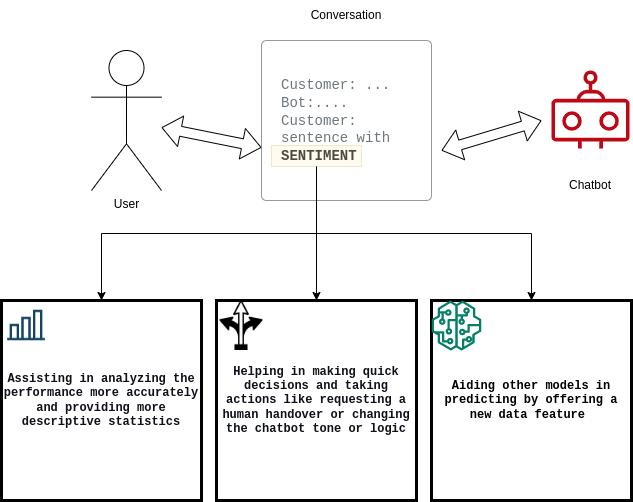
É importante que os chatbots quantifiquem os clientes satisfeitos ou insatisfeitos, bem como documentem a taxa de conversão de satisfeitos para insatisfeitos (ou vice-versa). Para cumprir esses requisitos, a solução da Widebot:
- Ajuda os usuários a analisar a performance do sistema de chatbot
- Melhora a capacidade de decisão do chatbot
- Auxilia outros modelos posteriores de machine learning (ML)
Desafios técnicos do desenvolvimento da análise de sentimentos
Os cientistas de dados da Widebot estão sempre inovando para aprimorar e otimizar seus modelos de aprendizado profundo, a fim de acompanhar as crescentes expectativas dos clientes. Para melhor atender os clientes de chatbots em árabe, eles trabalharam no desenvolvimento de uma nova solução de modelos de aprendizado profundo para a análise de sentimentos em árabe.
Os desafios desse projeto incluíram:
- Escalabilidade do modelo
- Tempo de resposta
- Grande volume de solicitações simultâneas
- O custo da execução
Como em muitas startups, inicialmente implantaram o modelo em uma infraestrutura autogerenciada e servidores de uso geral. No entanto, à medida que a startup cresceu, não conseguiram escalar o modelo de forma eficiente para acomodar o crescimento dos dados e os picos de solicitações simultâneas.
A Widebot começou a procurar uma solução para ajudar a equipe a se concentrar na criação de modelos rapidamente, sem dedicar tempo indevido ao gerenciamento e ajuste de escala da infraestrutura subjacente e dos fluxos de trabalho de operações de machine learning (MLOps).
Implantação do modelo no Amazon SageMaker
A Widebot escolheu o SageMaker porque ele fornece uma ampla seleção de opções de implantação de modelos e infraestrutura de ML para atender a todas as necessidades de inferência de ML. O SageMaker facilita a implantação de modelos de ML para as startups, com o melhor preço e performance.
“Felizmente, descobrimos que o Amazon SageMaker oferece total propriedade e controle em todo o ciclo de vida de desenvolvimento do modelo. As ferramentas simples e potentes do SageMaker nos permitem automatizar e padronizar a prática de MLOps para criar, treinar, implantar e gerenciar modelos com mais facilidade e rapidez do que era possível por meio de nossa infraestrutura autogerenciada”, afirma Mohamed Mostafa, cofundador e diretor de tecnologia (CTO) da Widebot.
A equipe da Widebot agora pode focar a criação e o aprimoramento dos modelos de ML para atender às expectativas dos clientes, enquanto o SageMaker se encarrega de configurar e gerenciar instâncias, compatibilidades de versões de software e versões de patches. O SageMaker também fornece métricas e logs integrados aos endpoints para continuar monitorando a integridade e a performance do modelo.
O Amazon SageMaker Inference Recommender ajudou a Widebot a escolher a melhor instância e configuração de computação para implantar seus modelos de ML a fim de otimizar a performance e o custo de inferência. O SageMaker Inference Recommender seleciona automaticamente o tipo de instância de computação, a contagem de instâncias, os parâmetros do contêiner e as otimizações do modelo para inferência a fim de maximizar a performance e minimizar os custos.
A Widebot também usa vários serviços da AWS para criar sua arquitetura, incluindo Amazon Simple Storage Service (Amazon S3), AWS Lambda, Amazon API Gateway e Amazon Elastic Container Registry (ECR):
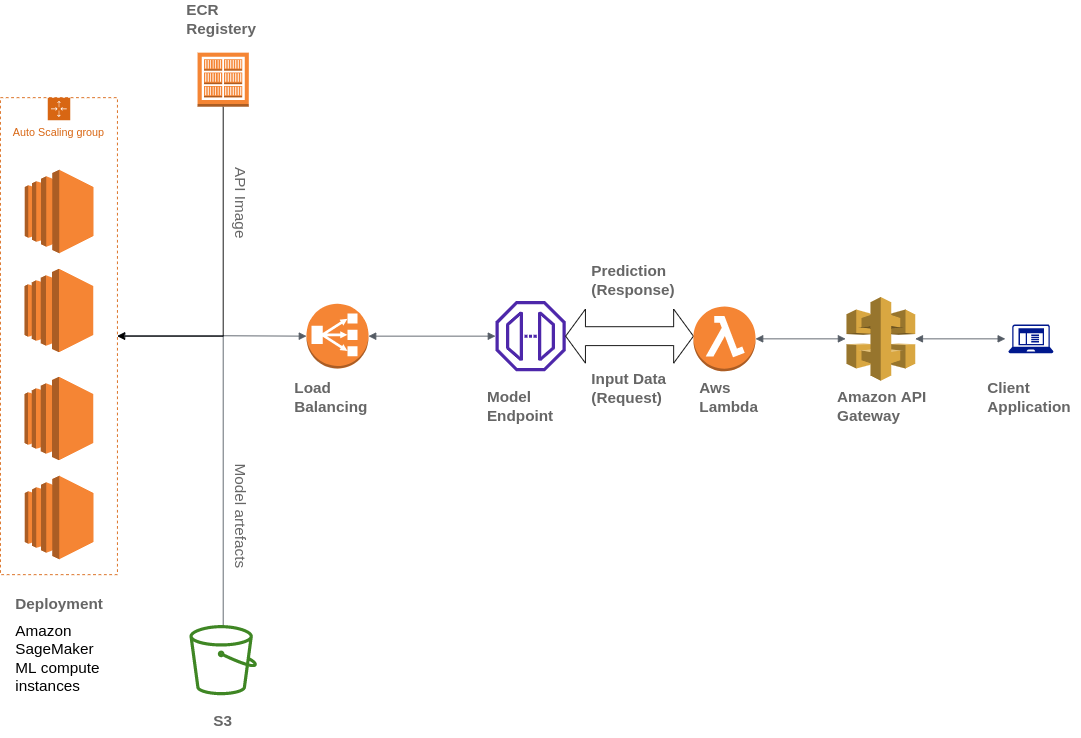
A Widebot estava procurando uma solução para publicar com segurança os modelos de ML que a empresa desenvolveu para seus clientes como um endpoint de API. Eles usaram o API Gateway, um serviço totalmente gerenciado, para publicar, manter, monitorar e proteger os endpoints de API dos modelos de ML implantados no SageMaker. O API Gateway é usado como um único ponto de entrada externo para os endpoints do SageMaker, o que os torna acessíveis pelos clientes de forma fácil e segura.
Os clientes interagem com o endpoint de inferência do SageMaker enviando uma solicitação de API para o endpoint do API Gateway. O API Gateway direciona as solicitações do cliente para o endpoint de inferência do SageMaker correspondente e invoca o endpoint para obter uma inferência do modelo. Posteriormente, o API Gateway recebe a resposta do endpoint do SageMaker e a direciona de volta, em uma resposta enviada ao cliente.
Visão geral da solução
Como a Widebot criou uma solução de sucesso para modelos de aprendizado profundo de análise de sentimentos em árabe? Estas foram as etapas seguidas:
Coleta e preparação do conjuntos de dados
Colete dezenas de milhares de amostras de dados de diferentes fontes de dados (públicas e internas).
Analise cuidadosamente os conjuntos de dados, aplique a rotulagem de dados e melhore a qualidade removendo as amostras irrelevantes.
A equipe de dados conduz um processo de anotação usando o Amazon SageMaker Ground Truth para anotar amostras suficientes de diferentes domínios e estilos de escrita para enriquecer o conjunto de dados usado.
Envie amostras por meio do pipeline de pré-processamento, antes de treinar o modelo usando aprendizado profundo para classificar o texto de entrada como positivo, negativo ou neutro, com a probabilidade para cada um.
Construção e treinamento do modelo
Use um modelo de rede neural convolucional (CNN) treinado usando o Keras e o TensorFlow.
Aplique várias iterações para testar diferentes pipelines, arquiteturas e tokenizadores de pré-processamento até alcançar a arquitetura que produz os melhores resultados em diferentes conjuntos de dados de amostra e de diferentes domínios.
Use um pipeline de pré-processamento nativo desenvolvido internamente para remover informações desnecessárias do texto: datas, URLs, citações, endereços de e-mail, pontuação (exceto '!?') e números.
Aplique etapas de normalização de texto em árabe, como remover sinais diacríticos e normalizar algumas letras que os usuários usaram de forma intercambiável, como (ء أ ئ ؤ إ) ou yaa (ي ى) ou outros caracteres.
Aplique uma raiz leve da palavra no texto que remove alguns sufixos e prefixos e reduz algumas palavras grandes em seu radical, por exemplo, (التعيينات) reduzido para (تعيين).
Salve o modelo, o pré-processador, os hiperparâmetros e os tokenizadores usando a serialização e exporte-os como arquivos.h5 e .pickle.
Implantação do modelo no Amazon SageMaker
Coloque o modelo em uma API, o endpoint de previsão. Esse endpoint aceita a entrada JSON do usuário final e transforma os dados em uma estrutura de dados mais fácil, os limpa e retorna os resultados de sentimento dos dados de entrada.
Crie uma imagem do Docker que contenha o código, todas as dependências e instruções necessárias para criar e executar os componentes em qualquer ambiente.
Faça upload dos artefatos do modelo em um bucket do Amazon S3 e da imagem do Docker no Amazon ECR.
Implante o modelo usando o SageMaker, selecionando o local da imagem no Amazon ECR e o URI dos artefatos no bucket do Amazon S3.
Crie um endpoint usando o SageMaker e utilize o API Gateway para publicar o endpoint para os clientes.
Tipo e volume de dados
Para criar seu modelo, os dados da Widebot consistem em aproximadamente 100 mil mensagens diferentes para treinamento e 20 mil mensagens para validação e teste. As mensagens:
- São provenientes de diferentes setores, como comércio eletrônico, alimentos e bebidas e serviços financeiros.
- Incluem avaliações de diferentes serviços ou produtos, por exemplo, avaliações de hotéis, avaliações de reservas, avaliações de restaurantes e avaliações de empresas.
- Têm um tom variado, desde uma linguagem muito formal até o uso de palavras profanas severas.
- Foram escritas em dialeto egípcio e árabe padrão moderno.
- Foram classificadas em uma das três classes: negativa, neutra ou positiva.
A seguinte tabela mostra exemplos de mensagens:
| Exemplo | Sentimento | Confiança |
| الخدمة لديكم مناسبة “Seu serviço é bom” | positiva | 0,8471 |
| شكرا لحسن تعاونكم “Agradecemos a sua cooperação” | positiva | 0,9688 |
| الخدمة والتعامل لديكم دون المستوى “Seu serviço está abaixo do padrão” | negativa | 0,8982 |
| حالة الجو سيئة جدا “O tempo está muito ruim” | negativa | 0,9737 |
| سأعاود الإتصال بكم وقت لاحق “Entrarei em contato com você mais tarde” | neutra | 0,8255 |
| أريد الإستعلام عن الخدمات “Quero saber mais sobre os serviços” | neutra | 0,9728 |
Resumo dos resultados
A Widebot testou seu modelo em diferentes conjuntos de dados de texto em árabe, em vários dialetos. Essas métricas foram medidas usando conjuntos de dados com milhares de amostras. A pontuação F1 é usada para medir a precisão do modelo com os diferentes conjuntos de dados. As médias macro e ponderadas da pontuação F1 são usadas para medir a precisão e performance gerais.
A precisão do modelo
O conjunto de dados de teste (20.679 amostras na proporção 5004:1783:13892)
| F1 Negativa | F1 Neutra | F1 Positiva | Precisão geral | Média macro | Média ponderada |
| 89,9 | 79,4 | 95,1 | 92,5 | 88,1 | 92,5 |
O tempo de resposta do modelo
A Widebot mediu o tempo de resposta usando a média (AVG), mínima (MIN) e máxima (MAX) em segundos por resposta (s/resposta):
- AVG: 0,106 s/resposta
- MIN: 0,088 s/resposta
- MAX: 0,957 s/resposta
A seguir, comparamos a métrica de tempo de resposta entre o uso de uma plataforma de computação de uso geral e o uso do Amazon SageMaker para hospedagem de modelos, ao implantar os mesmos conjuntos de dados com um tamanho médio de carga útil de 2 KB.
| Tempo total de resposta | Tempo total de resposta da plataforma de computação geral (instâncias do EC2: p2.xlarge) | Amazon SageMaker (instâncias do SageMaker: ml.m4.xlarge) |
| Média | 0,202 s/resposta | 0,106 s/resposta |
| Mínimo | 0,097 s/resposta | 0,088 s/resposta |
| Máximo | 8.458 s/resposta | 0,957 s/resposta |
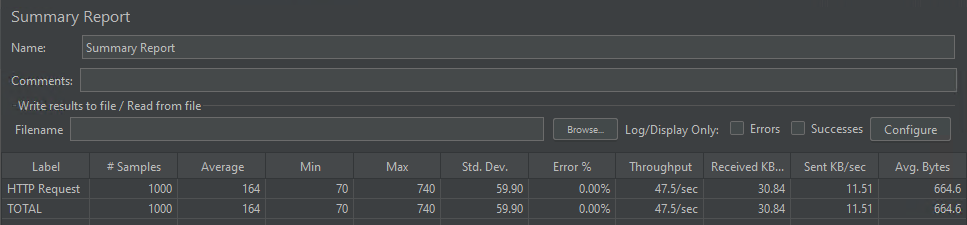
A simultaneidade do modelo
O modelo foi capaz de lidar com mil solicitações simultâneas atendidas em média em 164 milissegundos.
Conclusão
Este post mostra como os serviços da AWS ajudaram a Widebot a criar uma solução abrangente para extrair sentimentos do texto do chat em diferentes dialetos árabes, usando um modelo de aprendizado profundo hospedado no SageMaker.
O SageMaker ajudou a Widebot a inovar com mais rapidez e a implantar seu classificador de sentimentos para resolver o complexo problema de ML da extração de sentimentos de texto conversacional em árabe e publicá-lo como um endpoint RESTful público para os clientes acessarem com facilidade e segurança por meio do API Gateway.
Essa solução pode ser útil para muitos casos de uso semelhantes, nos quais os clientes desejam criar, treinar e implantar seu modelo de ML no SageMaker e publicar o endpoint de inferência de modelo para seus clientes de uma forma simples e segura, usando o API Gateway.
Para saber mais sobre diversidade linguística e como ajustar modelos de linguagem pré-treinados baseados em transformadores no Amazon SageMaker, leia esta publicação no blog.

Mohamed Mostafa
Mohamed Mostafa é cofundador e CTO da WideBot. Ele é apaixonado por aplicar práticas modernas de engenharia e desenvolver software de alta qualidade para melhorar a experiência dos usuários.

Ahmed Azzam
Ahmed Azzam é Arquiteto Sênior de Soluções, baseado em Dubai, Emirados Árabes Unidos. Ele é apaixonado por ajudar startups não apenas a projetar e desenvolver aplicações escaláveis, mas também a pensar em soluções inovadoras usando os serviços da AWS.
Como estava esse conteúdo?