¿Qué le pareció este contenido?
Cómo ayuda Amazon SageMaker a Widebot a ofrecer un análisis de opiniones en árabe
Las startups están familiarizadas con la importancia de crear excelentes experiencias para los clientes y el análisis de opiniones es una herramienta que ayuda en este sentido. Clasifica los datos como positivos, negativos o neutros basándose en técnicas de machine learning, como el análisis de textos y el procesamiento de lenguaje natural (NLP). Las empresas utilizan el análisis de opiniones para medir la satisfacción de los clientes con un producto o servicio determinado.
El análisis de opiniones puede ser particularmente difícil en el caso de los usuarios finales árabes: los habitantes de la región de Medio Oriente y África del Norte (MENA) hablan más de 20 dialectos del idioma árabe, de los que el árabe estándar moderno es el más común.
En esta entrada de blog, explicamos cómo Widebot usa Amazon SageMaker para implementar correctamente un clasificador de opiniones. Widebot es una de las principales plataformas de chatbots conversacionales de inteligencia artificial (IA) centrada en el árabe de la región MENA. Su clasificador de opiniones admite el árabe estándar moderno y el árabe dialectal egipcio, con gran precisión cuando se prueba en varios conjuntos de datos de diferentes dominios.
El modelo de Widebot se puede ajustar fácilmente después de recibir algunos cientos de muestras del nuevo dominio o conjunto de datos. Esto hace que la solución sea genérica y adaptable a diferentes dominios y casos de uso.
Características de un chatbot exitoso
Los chatbots son una herramienta útil para administrar y mejorar las experiencias de los clientes, así como para automatizar las tareas a fin de que los empleados puedan centrarse en el trabajo fundamental de la empresa. Las startups, en particular, están familiarizadas con el valor de utilizar los servicios administrados para poder dedicarse a las tareas más importantes para alcanzar el éxito.
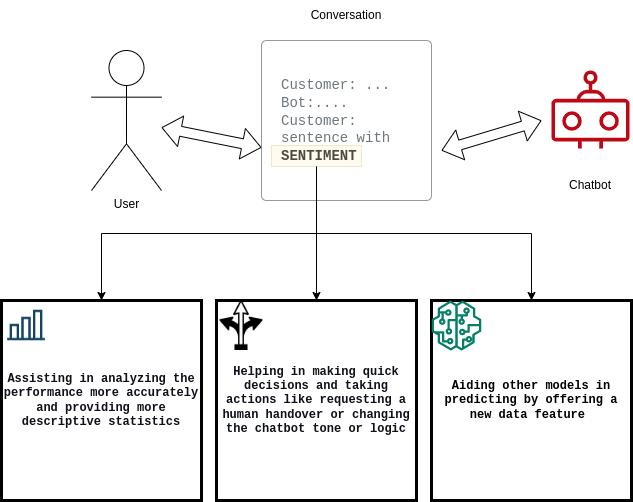
Es importante que los chatbots cuantifiquen los clientes satisfechos o insatisfechos y que documenten la tasa de conversión entre ambos (es decir, pasar de satisfecho a insatisfecho y viceversa). Para cumplir estos requisitos, la solución de Widebot hace lo siguiente:
- Ayuda a los usuarios a analizar el rendimiento del sistema de su chatbot
- Mejora la toma de decisiones del chatbot
- Ayuda a otros modelos descendentes de machine learning (ML)
Desafíos técnicos de la generación de análisis de opiniones
Los científicos de datos de Widebot siempre están innovando para mejorar y optimizar sus modelos de aprendizaje profundo a fin de cumplir con las crecientes expectativas de los clientes. Por ejemplo, en el caso de los clientes de chatbots en árabe, trabajaron en el desarrollo de una nueva solución para modelos de aprendizaje profundo de análisis de opiniones en ese idioma.
Entre los desafíos se incluían los siguientes:
- Escalabilidad de modelos
- Tiempo de respuesta
- Solicitudes de simultaneidad masivas
- Costo de ejecución
Como es el caso de muchas startups, al inicio implementaron el modelo en una infraestructura autoadministrada y en servidores de uso general. Sin embargo, cuando crecieron, ya no pudieron escalar el modelo de manera eficiente para adaptarlo al aumento de los datos y a los picos de solicitudes simultáneas.
En Widebot comenzaron a buscar una solución que los ayudara a centrarse en crear los modelos rápidamente, sin dedicar demasiado tiempo a administrar y escalar la infraestructura subyacente y los flujos de trabajo de las operaciones de machine learning (MLOps).
Implementación de modelos en Amazon SageMaker
Widebot eligió SageMaker porque ofrece una amplia variedad de opciones de implementación de modelos e infraestructura de machine learning para satisfacer todas sus necesidades de inferencia de ML. SageMaker facilita a las startups la implementación de este tipo de modelos al mejor precio y rendimiento.
“Afortunadamente, descubrimos que Amazon SageMaker nos otorga la propiedad y el control totales durante todo el ciclo de vida del desarrollo del modelo. Las herramientas sencillas y eficaces de SageMaker nos permiten automatizar y estandarizar la práctica de MLOps para crear, entrenar, implementar y administrar modelos de forma más fácil y rápida que con nuestra infraestructura autoadministrada”, afirma Mohamed Mostafa, cofundador y Chief Technology Officer (CTO) de Widebot.
El equipo de Widebot ahora puede centrarse en crear y mejorar sus modelos de ML para cumplir con las expectativas de sus clientes, mientras que SageMaker se encarga de configurar y administrar las instancias, la compatibilidad de las versiones de software y la aplicación de revisiones. SageMaker también proporciona métricas y registros integrados para que los puntos de conexión continúen con la supervisión del estado y rendimiento de los modelos.
El Recomendador de inferencias de Amazon SageMaker ayudó a Widebot a elegir la mejor instancia y configuración de computación para implementar sus modelos de machine learning a fin de obtener un rendimiento y costo de inferencia óptimos. El Recomendador de inferencias de SageMaker selecciona automáticamente el tipo de instancia de computación, el recuento de instancias, los parámetros del contenedor y las optimizaciones del modelo de inferencia para maximizar el rendimiento y minimizar los costos.
Widebot también utiliza varios servicios de AWS para crear su arquitectura, incluidos Amazon Simple Storage Service (Amazon S3), AWS Lambda, Amazon API Gateway y Amazon Elastic Container Registry (ECR):
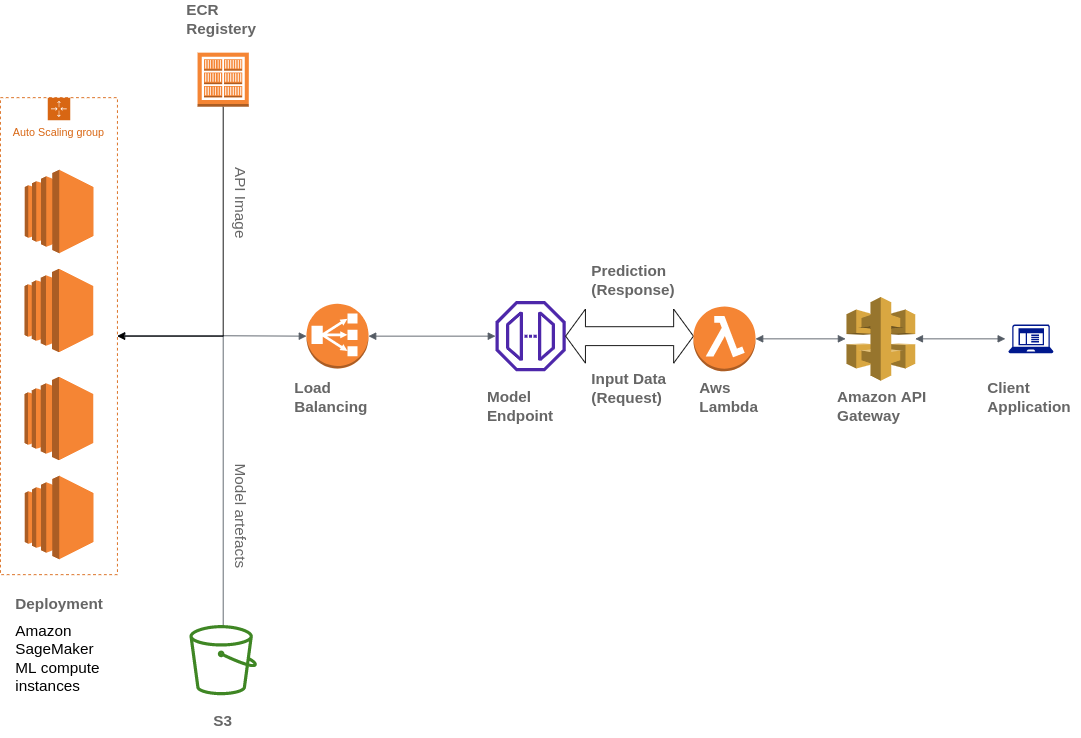
Widebot buscaba una solución para publicar de forma segura los modelos de ML que se habían desarrollado para sus clientes como punto de conexión de la API. Utilizaron API Gateway, un servicio totalmente administrado, para publicar, mantener, supervisar y proteger los puntos de conexión de la API de los modelos de machine learning implementados en SageMaker. API Gateway se utiliza como un único punto de entrada externo para los puntos de conexión de SageMaker, lo que permite que los clientes puedan acceder a ellos de forma fácil y segura.
Los clientes interactúan con el punto de conexión de inferencia de SageMaker al enviar una solicitud de API al punto de conexión de API Gateway. API Gateway asigna las solicitudes del cliente al punto de conexión de inferencia de SageMaker correspondiente y lo invoca para obtener una inferencia del modelo. Posteriormente, API Gateway recibe la respuesta del punto de conexión de SageMaker y la asigna de vuelta en una respuesta que se envía al cliente.
Información general sobre la solución
¿Cómo creó Widebot una nueva solución exitosa para los modelos de aprendizaje profundo de análisis de opiniones en árabe? Estos son los pasos que se siguieron:
Recopilación y preparación de conjuntos de datos
Se recopilan decenas de miles de muestras de datos de diferentes orígenes (tanto públicos como internos).
Se revisan los conjuntos de datos detenidamente, se aplica el etiquetado correspondiente y se mejora la calidad al eliminar las muestras irrelevantes.
El equipo de datos lleva a cabo un proceso de anotación y utiliza Amazon SageMaker Ground Truth para anotar suficientes muestras de diferentes dominios y estilos de escritura para enriquecer el conjunto de datos utilizado.
Se envían muestras mediante la canalización de preprocesamiento antes de entrenar el modelo con aprendizaje profundo. Esto permitirá clasificar el texto de entrada como positivo, negativo o neutro, además de conocer la probabilidad de cada uno.
Compilación y entrenamiento del modelo
Se usa un modelo de red neuronal convolucional (CNN) entrenado con Keras y TensorFlow.
Se aplican muchas iteraciones para probar diferentes canalizaciones de preprocesamiento, arquitecturas y generadores de tokens, hasta llegar a la arquitectura con los mejores resultados en diferentes conjuntos de datos de muestra y de distintos dominios.
Se utiliza una canalización de preprocesamiento nativa desarrollada de manera interna para eliminar la información innecesaria del texto: fechas, URL, menciones, direcciones de correo electrónico, signos de puntuación (excepto “!?”) y números.
Se aplican pasos de normalización de texto en árabe, como eliminar los signos diacríticos y normalizar algunas letras que los usuarios utilizaban indistintamente, como (ء أ ئ ؤ إ) o yaa (ي ى) u otros caracteres.
Se aplica una derivación ligera en el texto para eliminar algunos sufijos y prefijos y reducir algunas palabras demasiado largas a su raíz (por ejemplo, [لتعيينات] se reduce a [تعيين]).
Se guarda el modelo, el preprocesador, los hiperparámetros y los generadores de tokens mediante la serialización y se exportan como archivos .h5 y .pickle.
Implementación del modelo en Amazon SageMaker
Se integra el modelo en una API, el punto de conexión de predicción. Ese punto de conexión acepta la entrada JSON del usuario final y transforma los datos en una estructura más sencilla, los limpia y devuelve los resultados de opinión de los datos de entrada.
Se crea una imagen de Docker que contenga el código, todas las dependencias y las instrucciones necesarias para crear y ejecutar los componentes en cualquier entorno.
Se cargan los artefactos del modelo en un bucket de Amazon S3 y la imagen de Docker en Amazon ECR.
Se implementa el modelo con SageMaker; para ello, se selecciona la ubicación de la imagen en Amazon ECR y el URI de los artefactos del bucket de Amazon S3.
Se crea un punto de conexión con SageMaker y se publica para los clientes mediante API Gateway.
Tipo y volumen de datos
Para crear el modelo, los datos de Widebot constan de aproximadamente 100 000 mensajes diferentes para el entrenamiento y 20 000 para la validación y las pruebas. A continuación se indican algunas características de los mensajes:
- Provienen de diferentes sectores, como el comercio electrónico, los alimentos y bebidas y los servicios financieros.
- Esto incluye reseñas de diferentes servicios o productos. Por ejemplo, reseñas de hoteles, reservaciones, restaurantes y empresas.
- El tono varía desde un lenguaje muy formal hasta el uso de palabras soeces.
- Estaban escritos tanto en dialecto egipcio como en árabe estándar moderno.
- Se clasificaron en una de tres clases: negativo, neutro o positivo.
En la siguiente tabla se muestran ejemplos de mensajes:
| Ejemplo | Opinión | Confianza |
| الخدمة لديكم مناسبة “Su servicio es bueno” | positiva | 0,8471 |
| شكرا لحسن تعاونكم “Gracias por su cooperación” | positiva | 0,9688 |
| الخدمة والتعامل لديكم دون المستوى “Su servicio es deficiente” | negativa | 0,8982 |
| حالة الجو سيئة جدا “Hace muy mal tiempo” | negativa | 0,9737 |
| سأعاود الإتصال بكم وقت لاحق “Lo contactaré más tarde” | neutra | 0,8255 |
| أريد الإستعلام عن الخدمات “Quiero solicitar información sobre los servicios” | neutra | 0,9728 |
Resumen de resultados
Widebot probó su modelo con diferentes conjuntos de datos de texto en árabe en varios dialectos. Estas métricas se midieron con conjuntos de datos de miles de muestras. La puntuación F1 se utiliza para medir la precisión del modelo con los distintos conjuntos de datos. Los promedios macro y ponderado de la puntuación F1 se usan para medir la precisión y el rendimiento generales.
Precisión del modelo
El conjunto de datos de prueba (20 679 muestras en la proporción 5004:1783:13 892)
| F1 negativa | F1 neutra | F1 positiva | Precisión general | Promedio macro | Promedio ponderado |
| 89,9 | 79,4 | 95,1 | 92,5 | 88,1 | 92,5 |
Tiempo de respuesta del modelo
Widebot midió el tiempo de respuesta a partir del promedio (AVG), mínimo (MIN) y máximo (MAX) de segundos por respuesta (seg./respuesta):
- AVG: 0,106 seg./respuesta
- MIN: 0,088 seg./respuesta
- MAX: 0,957 seg./respuesta
A continuación, se compara la métrica del tiempo de respuesta entre el uso de una plataforma de computación de uso general y el uso de Amazon SageMaker para el alojamiento de modelos al implementar los mismos conjuntos de datos con un tamaño de carga promedio de 2 KB.
| Tiempo total de respuesta | Tiempo total de respuesta: plataforma de computación general (instancias de EC2: p2.xlarge) | Amazon SageMaker (instancias de SageMaker: ml.m4.xlarge) |
| Promedio | 0,202 seg./respuesta | 0,106 seg./respuesta |
| Mínimo | 0,097 seg./respuesta | 0,088 seg./respuesta |
| Máximo | 8,458 seg./respuesta | 0,957 seg./respuesta |
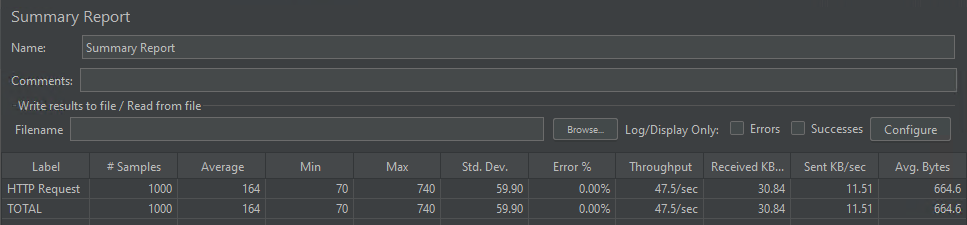
Simultaneidad del modelo
El modelo pudo gestionar 1000 solicitudes simultáneas atendidas en 164 milisegundos (en promedio).
Conclusión
En esta publicación se muestra cómo los servicios de AWS ayudaron a Widebot a crear una solución integral para extraer opiniones del texto de un chat en diferentes dialectos árabes mediante un modelo de aprendizaje profundo alojado en SageMaker.
SageMaker ayudó a Widebot a innovar más rápido y a implementar su clasificador de opiniones para resolver las complejidades que enfrenta el machine learning a la hora de extraer opiniones de texto conversacional en árabe y publicarlas como un punto de conexión RESTful público al que los clientes puedan acceder de forma fácil y segura mediante API Gateway.
Este enfoque podría ser útil para muchos casos de uso similares, en los que los clientes quieran crear, entrenar e implementar su modelo de machine learning en SageMaker y, a continuación, usar API Gateway para publicar el punto de conexión de inferencia del modelo para sus clientes de una manera sencilla pero segura.
Si está interesado en obtener más información sobre la diversidad lingüística y cómo ajustar modelos de lenguaje basados en transformadores previamente entrenados en Amazon SageMaker, puede leer esta entrada de blog.

Mohamed Mostafa
Mohamed Mostafa es cofundador y director de tecnología de WideBot. Le apasiona aplicar prácticas de ingeniería modernas y desarrollar software de alta calidad para mejorar la experiencia de los usuarios.

Ahmed Azzam
Ahmed Azzam es un arquitecto senior de soluciones con sede en Dubai, Emiratos Árabes Unidos. Le apasiona ayudar a las startups no solo a diseñar y desarrollar aplicaciones escalables, sino también a pensar en soluciones innovadoras con los servicios de AWS.
¿Qué le pareció este contenido?