Bagaimana konten ini?
PelajariQbiq: Menggunakan Citra Kontainer AWS Lambda & ML Terdistribusi untuk Mengoptimalkan Konstruksi
Qbiq: Menggunakan Citra Kontainer AWS Lambda & ML Terdistribusi untuk Mengoptimalkan Konstruksi
Posting dari tamu oleh Tim Qbiq dan Hilal Habashi. Arsitek Solusi Startup, AWS
Startup perangkat lunak real estat Qbiq memberikan mesin desain perencanaan ruang berbasis kecerdasan buatan (AI) yang menghasilkan denah lantai yang disesuaikan dalam jumlah besar, membandingkan alternatif, dan mengoptimalkan hasilnya. Sistem ini langsung memberikan saran untuk desain tata letak terbaik dalam batasan pemanfaatan ruang, biaya, waktu pembangunan, efisiensi, dan banyak faktor lainnya. Perhitungan intensif komputasi yang non-trivial ini dilakukan di belakang layar secara terdistribusi dengan membagi setiap permintaan tugas menjadi beberapa bagian. Khususnya, setiap rencana yang diterima dipecah menjadi beberapa sub rencana, dan setiap sub rencana ini diproses menggunakan machine learning (ML) dan pemrograman nonlinier. Pertama, kami menggunakan model ML untuk mengenali dan menganalisis berbagai alternatif tata letak yang berbeda, kemudian kami mengoptimalkan hasilnya menggunakan persamaan kuadratik.
Kami memilih AWS tepat di awal perjalanan kami karena fleksibilitas dan elastisitas yang ditawarkan AWS. AWS sangat cocok dengan kebutuhan daya komputasi kami yang signifikan di setiap langkah alur. Faktanya, selain beban kerja utama kami, tahap prapemrosesan kami, yang membagi rencana dan membutuhkan analisis spasial dan geometris serta parameter hiper yang berat mencari beban kerja nontrivial dengan sendirinya. Kami juga sangat bergantung pada cakupan jaringan penyokong dan waktu responsnya, luasnya layanan, dan model biaya bayar sesuai penggunaan. Semua ini memungkinkan kami untuk meningkatkan layanan kami dan menyediakannya kepada pelanggan sebanyak mungkin.
Untuk mendukung model bisnis kami, kami perlu menyediakan solusi perangkat lunak sebagai layanan (SaaS) yang cepat dan andal bagi klien kami, yang sangat berbeda dari apa yang ada di benak kami saat pertama kali memulai. Kami mengalami banyak tantangan selama proses membangun beban kerja terdistribusi yang disajikan dalam posting ini, dan seperti halnya perubahan arsitektur yang signifikan, kami perlu menemukan titik temu antara adopsi teknologi baru dan orientasi serta melatih tim teknisi untuk membangun produk terbaik yang kami bisa.
Tantangan
Mengembangkan algoritma ML terdistribusi
Kami memulai sebagai solusi SaaS cloud-native yang berjalan pada instans Amazon EC2. Untuk melakukan komputasi dalam jumlah besar dalam waktu yang terbatas (kurang dari 5 menit), kami harus membagi beban kerja kami ke dalam segmen-segmen kecil dan menjalankan subtugas secara terdistribusi. Saat kami mulai meningkatkan skala komputasi kami secara horizontal di AWS, kami juga harus mengerjakan ulang algoritma kami, menggunakan penyimpanan bersama untuk menyimpan berbagai model yang perlu kami jalankan, dan membuat antrean tugas yang diterima dari waktu ke waktu. Berkat Amazon EFS, dan Amazon SQS, kami dapat dengan cepat mengimplementasikan dan memelihara infrastruktur pendukung untuk kebutuhan komputasi terdistribusi kami dengan sedikit atau tanpa usaha dari tim kecil kami. EFS memungkinkan kami untuk berbagi penyimpanan di antara kontainer AWS Lambda kami dan menggunakan drive sebagai penyimpanan yang dipasang bersama untuk subproses kami.
Melakukan deployment dan memelihara algoritma kami
Penting bagi kami untuk melakukan deployment pada algoritma kami dalam pendekatan berbasis kontainer tanpa menggunakan alat berpemilik atau harus menulis skrip deployment kami sendiri dari awal. Kami menginginkan solusi yang dapat digunakan dengan pendekatan Git-ops tradisional dan mengabstraksikan lingkungan tempat kontainer kami berjalan. Kami ingin menskalakan ke luar daya komputasi yang tersedia berdasarkan permintaan dengan cepat dan tanpa perlu mengkhawatirkan penyediaan atau pengelolaan klaster kontainer. Kami memilih untuk menggunakan kontainer Lambda dengan EFS daripada solusi berbasis AWS Fargate atau EC2, dengan Amazon EBS karena kami menginginkan solusi yang sangat fleksibel dan dapat diskalakan dengan model bayar sesuai penggunaan yang tidak mengharuskan kami untuk melakukan orkestrasi kontainer dan tugas-tugas manajemen.
Menguji algoritma kami saat dimuat
Kami harus menulis pengujian menyeluruh untuk memverifikasi bahwa perhitungan kami berjalan dengan benar di seluruh klaster tugas terdistribusi kami, terlepas dari ukurannya, baik yang dijalankan secara lokal maupun di cloud. Kenyataannya, saat kami menjalankan dan mengatur beban kerja kami di EC2, kami menyadari bahwa semakin banyak instans perangkat lunak terdistribusi yang kami tambahkan, semakin sulit untuk mempertahankan konfigurasi dan menguji tumpukan kami secara keseluruhan. Tujuan utama kami adalah meningkatkan ketepatan cloud kami dan menghindari pemeliharaan dua set skrip penyiapan dengan basis kode yang sama. Selain itu, kami ingin dapat menguji produk kami pada skenario beban tinggi, tanpa konfigurasi yang ekstensif.
Kontainer AWS Lambda dalam Arsitektur Cloud kami
Dukungan yang baru-baru ini ditambahkan untuk citra kontainer khusus di Lambda telah memenuhi semua kebutuhan kami. Sangat mudah untuk menulis algoritma kami dan membungkusnya, bersama dengan semua dependensi kami, di dalam citra kontainer. Setelah melakukannya, kami harus melakukan mount volume, menambahkan file model baru ke dalam citra kontainer, dan menguji perangkat lunak kami secara lokal maupun di cloud. Mengadopsi kontainer telah menyederhanakan proses deployment kami dengan hanya mengandalkan alur berbasis Git tepercaya kami, bukan pada alat devops eksternal. Akhirnya, kami berhasil mengurangi manajemen sumber daya komputasi kami menjadi tugas sederhana untuk mengonfigurasi memori dan vCPU untuk Lambda kami, sebuah tugas yang semakin dipermudah dengan Lambda Power Tuning. Citra kontainer yang berjalan pada Lambda di lingkungan kami pada dasarnya adalah inti dari produk kami, dan berkat integrasi sumber peristiwa Lambda yang matang dengan layanan AWS lainnya, migrasi dari EC2 menjadi sangat mudah.
Gambaran umum tingkat tinggi:
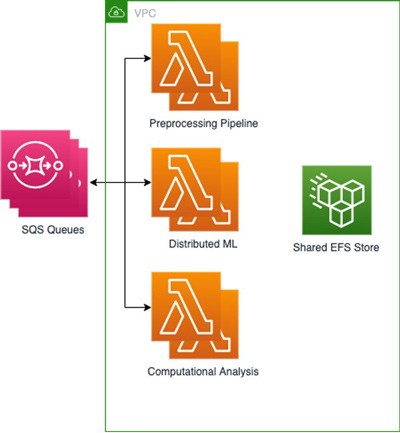
Kami telah membangun 3 fungsi Lambda menggunakan Amazon Elastic Container Registry (Amazon ECR) untuk menyimpan masing-masing dari 3 citra dasar kami; satu untuk setiap bagian dari proses, dengan dependensi dasar dan pengaturan yang disertakan sebagai file dan variabel lingkungan. Kemudian kami menghubungkan EFS untuk menyimpan output dari setiap tugas sehingga output tersebut akan cepat tersedia untuk tugas-tugas berikut, sementara model ML terdistribusi kami disimpan di Amazon S3. Karena proses ML terdistribusi kami mengurangi tugas-tugas lebih jauh lagi, sangat penting untuk memiliki sistem file bersama yang dapat dipasang dan diakses dalam setiap beban kerja berbasis kontainer. Pengaturan ini memungkinkan kami untuk berbagi file dengan throughput tinggi dan biaya tambahan rendah di antara berbagai fungsi Lambda. Kami menggunakan beberapa antrean SQS yang berisi informasi mengenai tugas, dengan file yang masuk.
Arsitektur ini memungkinkan kami untuk mencapai hasil dan waktu keseluruhan yang sama dengan deployment di atas klaster EC2 sekaligus mengurangi biaya dengan hanya membayar waktu algoritma yang berjalan. Sebagai contoh, kami dapat menghasilkan 50 hasil dalam 2 menit dengan memanggil 5.000 fungsi Lambda dengan eksekusi serentak maksimum sebesar 500, yang menghasilkan biaya rata-rata 1 USD per batch. Di sisi lain, menjalankannya di klaster EC2 dengan 500 inti paralel akan memakan biaya sekitar dua kali lipat dan memerlukan penyediaan klaster. Terakhir, para teknisi ML dan ilmuwan data kami dapat beroperasi di dalam lingkungan berbasis kontainer yang sudah mereka kenal dengan menggunakan satu set pengujian daripada menulis satu set unik untuk lingkungan tanpa kontainer yang berjalan di cloud seperti yang mereka lakukan sebelumnya.
Mengelola beban kerja kami
Untuk mengelola beban kerja ML terdistribusi kami dengan andal, kami mengimplementasikan manajer alur kerja berbasis grafik kami sendiri. Setiap permintaan tugas yang dikirim oleh pengguna dimulai dengan file yang diunggah dan namanya dicatat sebagai Nama Topik. Kemudian, kami membuat sub-grafik untuk setiap Nama Topik yang dapat berisi beberapa simpul di bawahnya, di mana satu simpul untuk setiap tugas komputasi yang akan diproses. Setiap simpul dalam sub-grafik tugas berisi representasi keadaan internal. Sisi-sisi dalam sub-grafik adalah fungsi dari input dan tugas berikutnya yang akan dijalankan.
Beban kerja kami saat ini adalah proses 3 langkah, yang berarti bahwa kami mengalikan jumlah bagian dengan tiga, di mana kami membagikan setiap tugas ke dalam bagian-bagian tersebut. Alur prapemrosesan memecah tugas dan file terkait menjadi beberapa bagian. Sub-grafik dibuat untuk setiap tugas, dan manajer alur kerja kemudian memuat tugas ke dalam sistem yang berisi banyak simpul. Kami mulai memproses simpul-simpul yang disisipkan secara paralel dengan menelusuri sisi grafik kami dan secara bersamaan memuat informasi status saat ini ke dalam fungsi Lambda berikutnya, setiap langkah dalam satu waktu. Manajer alur kerja mencatat data di simpul yang sesuai untuk setiap langkah proses dan bagian dari tugas serta melanjutkan hingga semua data untuk tugas tersebut diproses. Terakhir, kami menggabungkan hasilnya dan mengomunikasikannya kepada pelanggan kami.
Manajer alur kerja berkomunikasi dengan fungsi Lambda melalui API REST menggunakan dua jenis permintaan POST:
1) `RequestRequired` adalah permintaan sinkron yang dapat menangani ukuran muatan yang besar, tetapi memiliki batasan waktu respons 30 detik.
2) `Event` adalah permintaan asinkron dan berfungsi dengan baik untuk mengirim beberapa tugas paralel dengan muatan kecil.
Merancang manajer alur kerja:
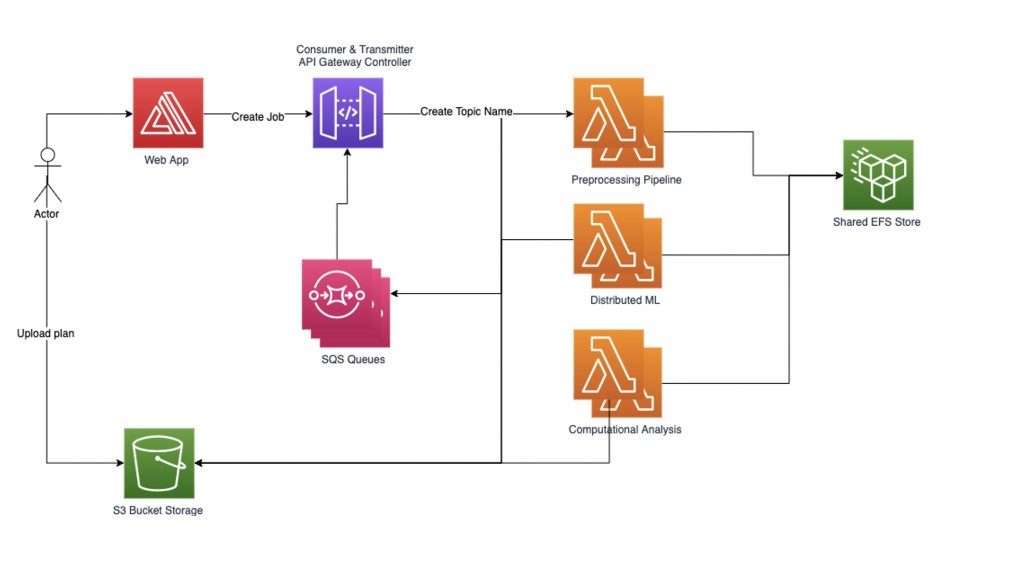
Manajer alur kerja menyiapkan dua thread pembantu: pemancar dan konsumen. Thread pemancar bertanggung jawab untuk memeriksa antrean tugas asinkron dan mengelola tugas mana yang akan diaktifkan dengan mengirimkannya ke fungsi Lambda. Kita dapat mengontrol jumlah tugas yang aktif secara simultan sebagai parameter untuk mengontrol konkurensi Lambda yang aktif. Saat sebuah tugas dikirim untuk diproses oleh fungsi lambda, permintaan berisi nama antrean SQS yang akan digunakan untuk menulis respons. Thread konsumen bertanggung jawab untuk mengonsumsi pesan dari antrean SQS dan mendistribusikan respons tugas yang masuk sesuai dengan topiknya.
Karena kami melakukan deployment pada sejumlah besar tugas dengan kumpulan pekerja yang terbatas agar tidak melebihi batas konkurensi, simpul-simpul yang tidak konvergen atau membutuhkan waktu komputasi yang tidak teratur dapat secara signifikan mengurangi performa sistem. Agar terlindung dari tugas yang menggantung atau terlalu lama, digunakan sistem tiga batas waktu. Batas waktu pertama adalah batas waktu lambda dasar yang dikonfigurasikan saat mengatur fungsi Lambda. Batas waktu ini seharusnya cukup longgar karena kemungkinan besar tidak akan pernah tercapai. Batas waktu kedua ada di dalam setiap fungsi lambda. Saat handler fungsi dipanggil, fungsi ini akan memulai sebuah thread tambahan dan menunggu selama jangka waktu tertentu. Jika batas waktu tercapai, fungsi lambda mengirimkan kembali respons kesalahan batas waktu ke antrean. Yang terakhir adalah batas waktu topik di manajer alur kerja yang agnostik terhadap fungsi Lambda dan terpicu jika lebih dari jumlah waktu tertentu berlalu sejak posting tugas terakhir dikirim di bawah topik ini.
Untuk mencapai performa tinggi dengan pemanasan yang cepat (menurunkan waktu mulai), kami menggunakan fitur Konkurensi yang Tersedia pada fungsi Lambda. Kami juga menggunakan panggilan inisialisasi untuk memanaskan fungsi Lambda dan menyiapkan data. Throughput EFS disediakan untuk memungkinkan MiB/detik yang tinggi untuk menghilangkan kemacetan saat beberapa lambda mengakses data yang disimpan pada EFS secara paralel.
Kesimpulan
Di Qbiq, kami menghadirkan teknologi AI, desain generatif, dan optimisasi yang canggih untuk perencanaan real estat. Menggunakan kontainer citra AWS Lambda memungkinkan kami untuk dengan mudah menskalakan ke ratusan prosesor cloud yang dimuat dengan pengalaman arsitektur ratusan tahun, memproses permintaan perencanaan, menganalisis alternatif tata letak yang berbeda, dan mengoptimalkan hasilnya.
Kami memberikan alternatif konsep terbaik kepada pelanggan kami dengan mempertimbangkan pemanfaatan, biaya, waktu pembangunan, efisiensi, dan banyak lagi. Untuk informasi selengkapnya mengenai Qbiq, silakan kunjungi situs web kami, qbiq.ai.

AWS Editorial Team
Tim Pemasaran Konten AWS Startupss bekerja sama dengan Startups dari semua ukuran dan di semua sektor untuk memberikan konten luar biasa yang mendidik, menghibur, dan menginspirasi.
Bagaimana konten ini?