Wie war dieser Inhalt?
LernenWie Snorkel AI durch die Skalierung von Machine-Learning-Workloads mithilfe von Amazon EKS Kosteneinsparungen von über 40 % erzielte
Wie Snorkel AI durch die Skalierung von Machine-Learning-Workloads mithilfe von Amazon EKS Kosteneinsparungen von über 40 % erzielte
Startups für Machine Learning (ML) verwenden häufig viel Rechenleistung, da sie große Modelle mithilfe von High-End-GPUs trainieren und sie für Inferenzen in großem Umfang einsetzen. AWS Startups arbeitet von der Gründung bis zum Börsengang mit Startups zusammen und hat Tausenden von Gründern und Innovatoren im Bereich der künstlichen Intelligenz (KI) geholfen, ihr Unternehmen auf Amazon Elastic Kubernetes Service (Amazon EKS) aufzubauen. Amazon EKS ist eine beliebte Wahl für die Erstellung und das Hosten von ML-Modellen, da es die Flexibilität von Kubernetes mit der Sicherheit und Widerstandsfähigkeit eines von AWS verwalteten Dienstes verbindet, der für die Erstellung hochverfügbarer containerisierter Workloads optimiert ist.
Snorkel AI ist ein solches Unternehmen, das von Amazon EKS profitiert. Snorkel AI versetzt Fortune-500-Unternehmen, Bundesbehörden und KI-Innovatoren in die Lage , Basismodelle (FMs) und große Sprachmodelle (LLMs) zu erstellen, anzupassen und zu destillieren, damit sie mit hoher Genauigkeit auf domänenspezifischen Datensätzen arbeiten. Mithilfe des datenzentrierten Ansatzes von Snorkel für die KI-Entwicklung haben Unternehmen produktionsreife KI-Dienste für Anwendungsfälle wie die Bearbeitung von Versicherungsansprüchen, die Verbreitung von Finanzdaten, die Analyse von klinischen Studien und die Beschleunigung des proaktiven Bohrlochmanagements für Offshore-Bohrungen entwickelt.
In den letzten Monaten hat das Snorkel-Team hart daran gearbeitet, die einzigartigen Herausforderungen beim Entwurf einer effizienten Infrastruktur zur Unterstützung von ML-Entwicklungsworkloads zu bewältigen, ohne die Infrastrukturkosten zu erhöhen, die Geschwindigkeit der Entwickler zu verringern oder die Benutzererfahrung zu beeinträchtigen. Ihr oberstes Ziel war es, die Cluster-Rechenkosten für Snorkel Flow, ihre End-to-End-ML-Plattform, um mehr als 40 % zu senken.
Ein Überblick über Snorkel Flow
Die KI-Datenentwicklungsplattform Snorkel Flow von Snorkel ermöglicht es Datenteams, KI-Anwendungen schnell zu erstellen, indem sie eine iterative Schleife aus programmatischer Kennzeichnung, schnellem Modelltraining und Fehleranalyse einsetzen. Jedes Projekt beginnt, wenn Benutzer eine kleine Anzahl von Kennzeichnungsfunktionen erstellen.
Labeling-Funktionen verwenden einfache Heuristiken, externe Datenbanken, Legacy-Modelle oder sogar Aufrufe großer Sprachmodelle, um Labels auf unbeschriftete Datenmengen anzuwenden, die auf verschlüsselter Expertenintuition basieren. Der schwache Überwachungsalgorithmus der Plattform kombiniert diese regelbasierten Funktionen, um die wahrscheinlichste Bezeichnung für jeden Datensatz zu ermitteln. Die Benutzer trainieren dann ein einfaches Modell auf der Grundlage dieser probabilistischen Datenpunkte und bewerten die Auswirkungen der einzelnen Beschriftungsfunktionen. In der Analysephase untersuchen Benutzer Teile der Daten, bei denen das Modell unterdurchschnittlich abschneidet. Anschließend erstellen oder ändern sie Beschriftungsfunktionen, trainieren ein weiteres Schnellmodell und setzen die Schleife fort. Wenn Benutzer mit der Qualität ihrer Labels zufrieden sind, erstellen sie ein endgültiges Modell auf einer Architektur aus dem Modellzoo—von der logistischen Regression bis hin zu FMs—und exportieren es zur Bereitstellung.
Aufgrund der Art dieses Workflows erlebt die Infrastruktur von Snorkel Flow unterschiedliche Perioden mit hoher Rechenauslastung. Die Betriebskosten stiegen natürlich, je größer der Kundenstamm und die Möglichkeiten der ML-Produkte von Snorkel Flow wurden. Um ein effizientes Wachstum zu erreichen, wollte Snorkel herausfinden, wie die Margen erhöht werden können, während gleichzeitig modernste ML-Software eingesetzt wird. Snorkel implementierte die folgenden Methoden, um die Rechenkosten für Cluster um mehr als 40 % zu senken.
Lösungen für die Cloud-Kostenoptimierung
Software-as-a-Service (SaaS)-Startups haben häufig die Möglichkeit, ihre Cloud-Ausgaben zu optimieren. Es ist wichtig, die einzigartigen Faktoren zu verstehen, die diese Kosten beeinflussen.
Für Snorkel gab es zwei signifikante Faktoren:
- ML-Entwicklungsworkloads erfordern häufig spezielle und teure Hardware wie GPUs. In der Regel sind diese Workloads von Natur „sprunghaft“.
- Fortune-500-Unternehmen und große Bundesbehörden nutzen Snorkel, darunter große Finanzinstitute mit hoch entwickelten IT-Abteilungen, die spezifische Bereitstellungs- und Datenschutzanforderungen haben, mithilfe einer containerisierten Plattform.
Das Team von Snorkel ist sehr daran interessiert, Systeme zu entwickeln, die eine effiziente Skalierung ohne einen linearen Anstieg der Infrastrukturkosten ermöglichen. Aus diesem Grund entwickelte Snorkel eine umfassende Autoscaling-Lösung, die auf seine ML-Workloads auf Amazon EKS zugeschnitten ist, um Bedenken hinsichtlich der Cloud-Kosten auszuräumen. Diese Lösung beschleunigte nicht nur Workloads, die Burst-Computing erfordern, sondern erreichte auch ihre Ziele zur Kostensenkung.
Neben der Autoscaling-Lösung trugen unter anderem folgende Strategien zur Senkung der Cloud-Kosten um über 40 % bei:
- Zusammenarbeit mit technischen Führungskräften und dem AWS-Team bei der Einführung von Savings Plans durch Optimierungen der Cloud-Konfiguration.
- Richtige Dimensionierung der Ressourcen durch Überwachung der Knotenauslastung mit Prometheus und Beratung mit Backend-Ingenieuren, um den Bedarf an Plattformkomponenten zu ermitteln.
- Umstellung auf kostengünstige Typen virtueller Maschinen (VM) auf Amazon EKS und Nutzung von Amazon Elastic Compute Cloud (Amazon EC2)-Instances mit mehreren GPUs für ein besseres Preis-Leistungs-Verhältnis.
- Einführung interner Prozessänderungen, bei denen Ingenieure mit Teams mit Kundenkontakt zusammenarbeiteten, um ungenutzte Rechenleistung zu minimieren.
In diesem Beitrag beschreibt Snorkel den Prozess zur Bewältigung dieser Skalierungsherausforderungen, um den Entwurf einer besseren Infrastruktur für ML-Systeme zu erleichtern. Wenn Sie neu bei Kubernetes sind, lesen Sie den Beitrag Einführung in Kubernetes von Snorkel, um mehr über die Grundlagen und das Machine Learning auf Kubernetes zu erfahren: Weisheit bei Snorkel, um mehr über ihre bisherige Reise mit Kubernetes zu erfahren.
So sieht Snorkel Flow auf AWS aus
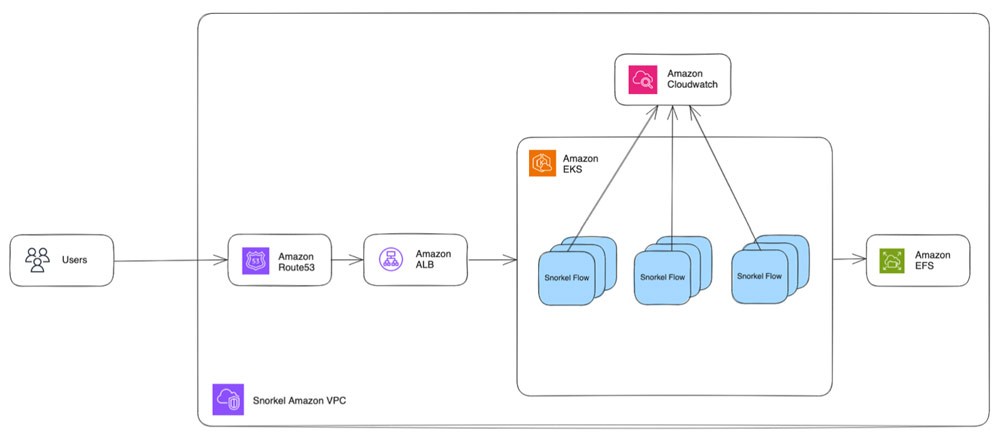
In der Praxis folgt die Interaktion von Snorkel Flow mit AWS der folgenden Reihenfolge. Da die Snorkel-Flow-Plattform stark von Containern abhängig ist, verlief die Migration zu AWS nahezu reibungslos.
- Benutzer erreichen ihre Snorkel-Flow-Instance über ihren Webbrowser, der einer Regel in Amazon Route 53 zugeordnet ist.
- Route 53 leitet die Anfrage an einen Application Load Balancer weiter.
- Der Application Load Balancer leitet die Anfrage dann an Snorkel-Flow-Pods weiter, die auf einem gemeinsam genutzten EKS-Cluster ausgeführt werden. Snorkel stellte den EC2-Instance-Typ von m5 auf m6a um, um die Kosten zu optimieren. Dies führte zu einer Recheneinsparung von 10 % bei vernachlässigbaren Leistungseinbußen, basierend auf den Kosten pro Stunde für dieselbe CPU und denselben RAM.
- Darüber hinaus wurde ein Upgrade von einer einzelnen g4dn.8xlarge-GPU-Instance auf eine g4dn.12xlarge-Multi-GPU-Instance durchgeführt, wodurch 4x so viele GPU-Pods bedient werden konnten.
- Jede Snorkel-Flow-Instance verwendet ein Amazon Elastic File System (Amazon EFS)-Volume, um Dateien auf der Festplatte zu speichern.
- Eine selbst gehostete Redis-Warteschlange auf einem Pod auf der EC2-Instance enthält die eingehenden Jobs und wartet darauf, dass Worker-Pods sie annehmen.
- EKS-Metriken werden an Amazon CloudWatch übertragen, und benutzerdefinierte Skripte überwachen die Protokolle auf Cluster-Leistungsanomalien.
Diese Architektur hat Snorkel-Flow-Benutzern ein stabiles und flottes Erlebnis beschert.
Skalierung überdenken
Vor der in Abbildung 1 beschriebenen Architektur verwendeten frühe Iterationen der Infrastruktur von Snorkel feste Ressourcen. Die Benutzer von Snorkel teilten mit, dass die Ausführung dieser überlasteten Workloads zu lange dauern könnte und sich daher negativ auf ihre Benutzererfahrung auswirkte.
Die manuelle Skalierung von Rechenressourcen erwies sich als nicht skalierbar und fehleranfällig, was zu hohen Cloud-Kosten führte, auch in Zeiten geringer Nutzung. Es war das Schlimmste aus beiden Welten: niedrige Cloud-Kosteneffizienz und Leistung, die langsamer als nötig war.
Um diesen Herausforderungen zu begegnen, implementierte Snorkel Autoscaling auf mehreren Ebenen in seiner Infrastruktur, wie in den folgenden Abschnitten beschrieben.
Entwurf einer skalierbaren Infrastruktur unter Berücksichtigung der Kosteneffizienz
Die Kubernetes-Distribution von Snorkel Flow umfasst eine Reihe von Bereitstellungen, die in einem EKS-Cluster ausgeführt werden, der Pods enthält, auf denen verschiedene Komponenten der Plattform ausgeführt werden.
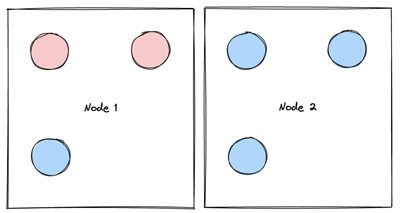
Wie in Abbildung 2 dargestellt, hat das Snorkel-Team ein neues Konzept für Kubernetes-Pods eingeführt, um die besonderen Herausforderungen bei der Arbeit mit Bursty-Compute-Workloads zu bewältigen: die semantische Kategorisierung als „fest“ oder „flexibel“.
- Pods, die repariert sind, können nicht sicher von Knoten zu Knoten verschoben werden, entweder weil sie wichtige In-Memory-Status verlieren (z. B. laufende Rechenaufträge ohne Checkpointing) oder um vermeidbare Ausfallzeiten für grundlegende Plattformkomponenten (z. B. den Orchestrator für den Ray-Cluster) zu minimieren.
- Pods, die flexibel sind, können sicher auf einen neuen Knoten verschoben werden. Diese Unterscheidung ist im Zusammenhang mit der automatischen Skalierung von Bedeutung, da beim Downscaling von Knoten Pods verschoben werden, die nicht ausgelastet sind, wenn diese beendet werden.
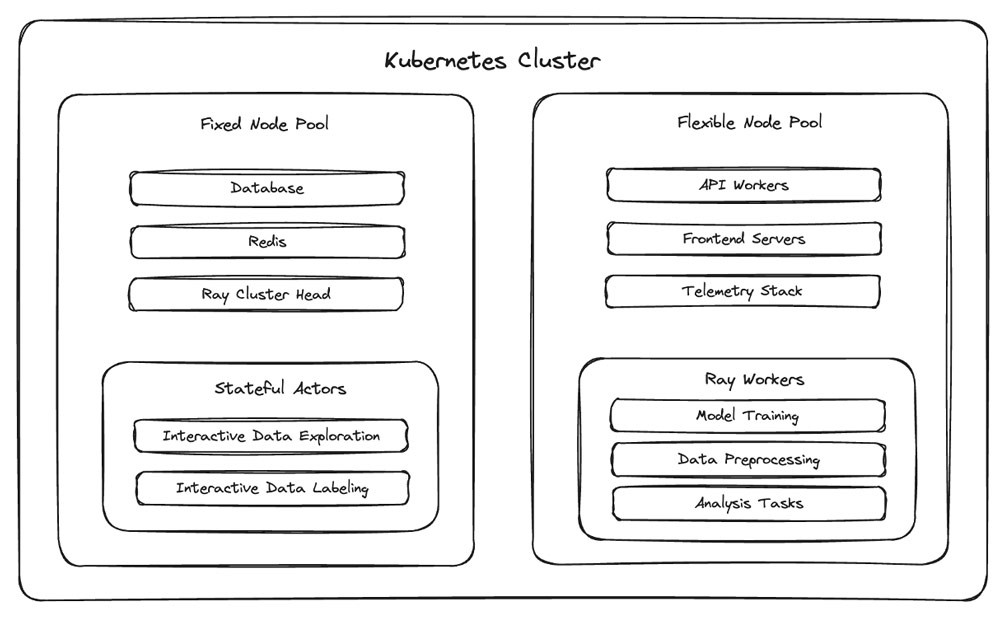
Dieses feste/flexible Framework bietet Snorkel eine domänenspezifische Möglichkeit, automatisiertes Cluster-Downscaling zu ermöglichen, sodass sie den Cluster-Autoscaler auf Amazon EKS aktivieren können, ohne dass ihre Finanzabteilung ihnen jede Stunde eine Nachricht sendet.
Der ursprüngliche Ansatz von Snorkel bestand darin, podDisruptionBudgets auf dem EKS-Cluster bereitzustellen, um zu verhindern, dass der Cluster-Autoscaler tagsüber flexible Pods bewegt und feste Pods überhaupt bewegt. Dieser Ansatz war zwar effektiv, ließ das Snorkel-Team jedoch unzufrieden, da er weitaus weniger Knoten herunterskalierte, als theoretisch optimal war.
Um diesem Problem zu begegnen, setzte Snorkel auf eine Optimierung der Pod-Planung, bei der feste Pods in eine kleine feste Gruppe von Knoten isoliert wurden. Dabei wurden flexible Pods und Worker-Pods (die als feste Pods betrachtet werden, aber aufgrund der Autoskalierung der Worker-Knoten kurzlebig sind) in der verbleibenden flexiblen Gruppe von Knoten eingeplant.
Diese Änderungen ermöglichten es Snorkel, die flexiblen Knoten nachts effizient zu verkleinern, wenn es sicher war, die flexiblen Pods zu bewegen und die große Mehrheit der Worker-Pods herunterzuskalieren.
Durch die effiziente Herunterskalierung der überwiegenden Mehrheit der Knoten des Clusters (d. h. der flexiblen Knoten) konnte Snorkel sein Ziel erreichen, die Cloud-Kosten für das Hosten von Snorkel Flow um über 40 % zu senken.
Weitere Informationen zur Autoscaling-Lösung von Snorkel
Snorkel unterteilt die Implementierung der im vorherigen Abschnitt beschriebenen Lösung in drei aufeinander folgende Schritte:
- Zunächst implementierte Snorkel „Worker Autoscaling“, einen benutzerdefinierten Redis-basierten Autoscaling-Dienst, der es ihren Worker-Pods ermöglicht, basierend auf Jobs in den Warteschlangen der Mitarbeiter hoch- und herunterzuskalieren.
- Zweitens implementierten sie das „Cluster-Autoscaling“, indem sie ihre Kubernetes-Bereitstellungen so umkonfiguriert haben, dass der Kubernetes-Cluster-Auto-Scaler die Knoten nicht nur herunterskalieren, sondern auch hochskalieren kann.
- Drittens implementierte Snorkel „Optimierungen beim Herunterskalieren von Knoten“, indem feste Pods zu einer kleinen Gruppe fester Knoten gruppiert wurden, um zu verhindern, dass feste Pods das Herunterskalieren der verbleibenden Knoten stören.
Worker-Autoscaling
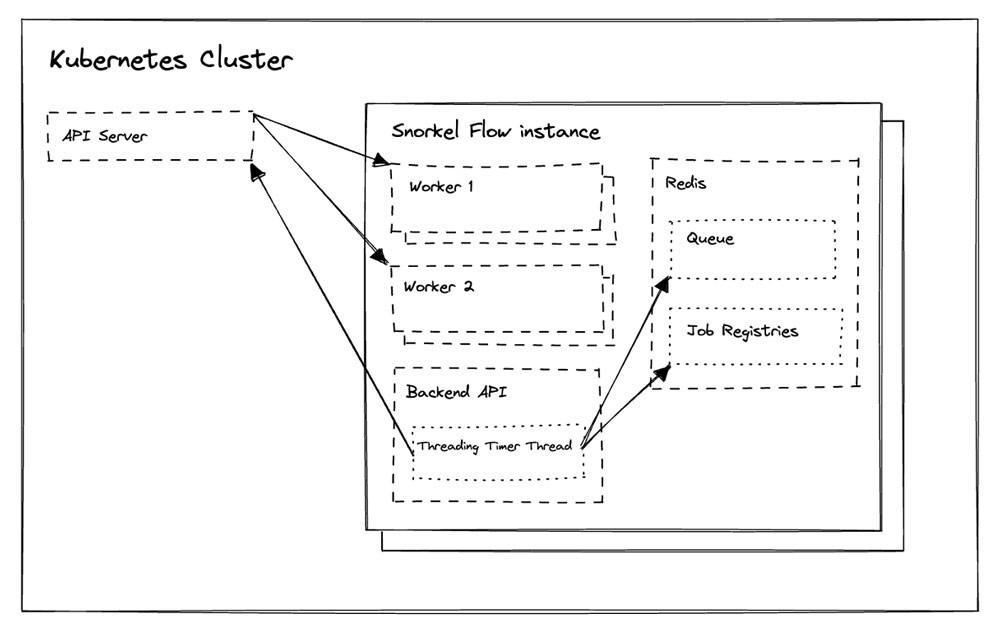
Die Snorkel-Flow-Plattform abstrahiert die Rechenleistung in ein Paradigma, in dem Jobs in Redis-Warteschlangen warten und Worker als Prozesse in Worker Pods laufen.
Snorkel implementierte eine Worker-Autoscaling-Lösung (Abbildung 3) für Worker-Pods, indem es eine wiederkehrende Funktion in der Backend-API von Snorkel Flow ausführte. Diese Funktion überprüft alle paar Sekunden, ob der Kubernetes-Cluster und Redis sowohl für das Hoch- als auch für das Herunterskalieren in Frage kommen.
Wenn Jobs in einer oder mehreren relevanten Redis-basierten Warteschlangen warten, fordert die Funktion die Kubernetes-API auf, zusätzliche Worker-Pods für die Verarbeitung dieser Jobs bereitzustellen. Wenn die Redis-Warteschlange leer ist und keine laufenden Jobs in der Jobregistrierung vorhanden sind, wird die Kubernetes-API aufgefordert, die Worker-Pods zu löschen, um reservierte CPU- und RAM-Ressourcen freizugeben.
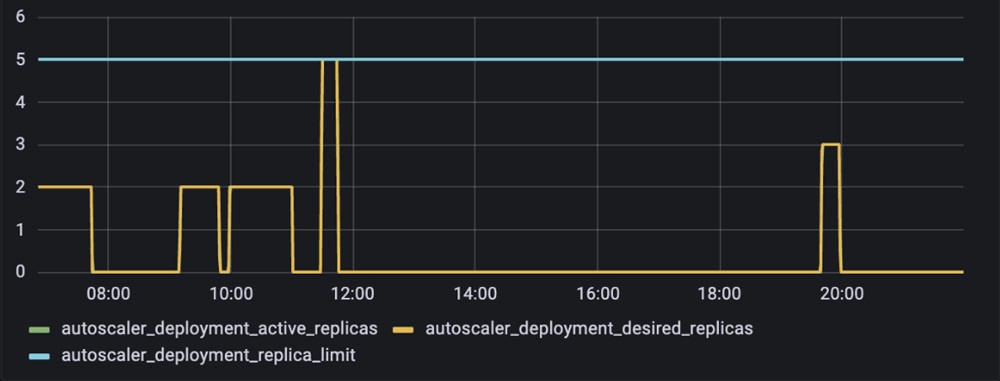
Wie in Abbildung 4 dargestellt, wurden die Worker-Pods von Snorkel Flow mit der Einführung dieser Worker-Autoscaling-Implementierung kurzlebig und erschienen nur dann im Cluster, wenn Jobs verarbeitet werden mussten.
Cluster-Autoscaling
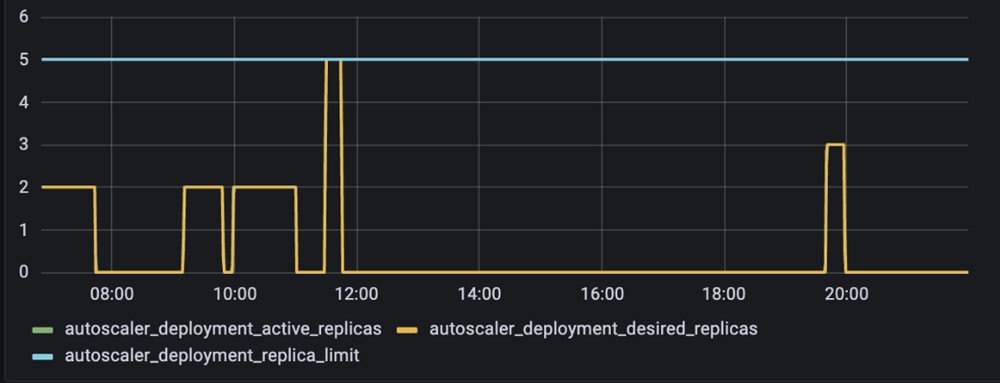
Die Ressource PodDisruptionBudget schützt bestimmte Pods vor Störungen (z. B. freiwilligen Neustarts), indem sie die Angabe der maximalen Anzahl von Pod-Replikaten ermöglicht, die zu einem bestimmten Zeitpunkt nicht verfügbar sein können. Wie in Abbildung 5 dargestellt, wird durch die explizite Festlegung dieses Werts für eine Bereitstellung auf 0 sichergestellt, dass das Cluster-Autoscaling die Knoten, auf denen die Pods der Bereitstellung ausgeführt werden, nicht herunterskaliert.
Die Implementierung dieser Ressource auf gehosteten Snorkel-Flow-Instances ermöglichte es dem Cluster-Autoscaler, nicht ausgelastete Knoten sicher herunterzuskalieren. Die Kosteneinsparungen, die Snorkel erzielte, waren jedoch marginal — sie waren immer noch nicht in der Lage, den Großteil ihrer Knoten herunterzuskalieren, da alle Snorkel-Flow-Pods durch ein zugehöriges podDisruptionBudget geschützt waren.
Bei näherer Betrachtung stellte das Team von Snorkel fest, dass dieser Schutz nicht immer existieren muss. Die Workloads sind sehr hoch und die meisten Benutzerinteraktionen mit Snorkel Flow finden während des Arbeitstages des Kunden statt, sodass es sicher ist, diesen Schutz außerhalb der Geschäftszeiten zu lockern. Ähnlich wie beim Worker-Autoscaling implementierte Snorkel eine wiederkehrende Funktion, die podDisruptionBudgets für die flexiblen Pods einer Instance über Nacht „ausschaltete“, indem die maximale Anzahl nicht verfügbarer Pod-Replikate von 0 auf 1 gesetzt wurde (Abbildung 6). Die frühere Lösung zum Autoscaling von Workern in Kombination mit dem ClusterAutoscaler- und der PodDisruptionBudget-Feature war in der Lage, viel mehr unausgelastete Worker-Knoten herunterzuskalieren als zuvor. Kunden, die Snorkel Flow in ihrer Cloud einsetzen, können dies nach Bedarf konfigurieren.
Optimierungen beim Herunterskalieren von Knoten
Trotz dieser Verbesserungen stellte Snorkel fest, dass die Mehrheit der nicht ausgelasteten Knoten überhaupt nicht herunterskaliert wurde.
Bei weiteren Untersuchungen stellte Snorkel fest, dass das Problem darauf zurückzuführen war, dass feste und flexible Pods denselben Knoten besetzen. Dies war problematisch, weil ein fester Pod, der pseudozufällig einem Knoten zugewiesen wurde, der flexible Pods enthält, diesen Knoten „anheften“ und so verhindern würde, dass er herunterskaliert wird, selbst wenn er nicht ausgelastet ist. Diese mangelnde Kontrolle über die Planung fester Pods führte zu Perioden, in denen die überwiegende Mehrheit der Knoten des Clusters nicht herunterskaliert werden konnte, obwohl sie viel mehr Rechenleistung zur Verfügung stellten, als zu diesem Zeitpunkt benötigt wurde.
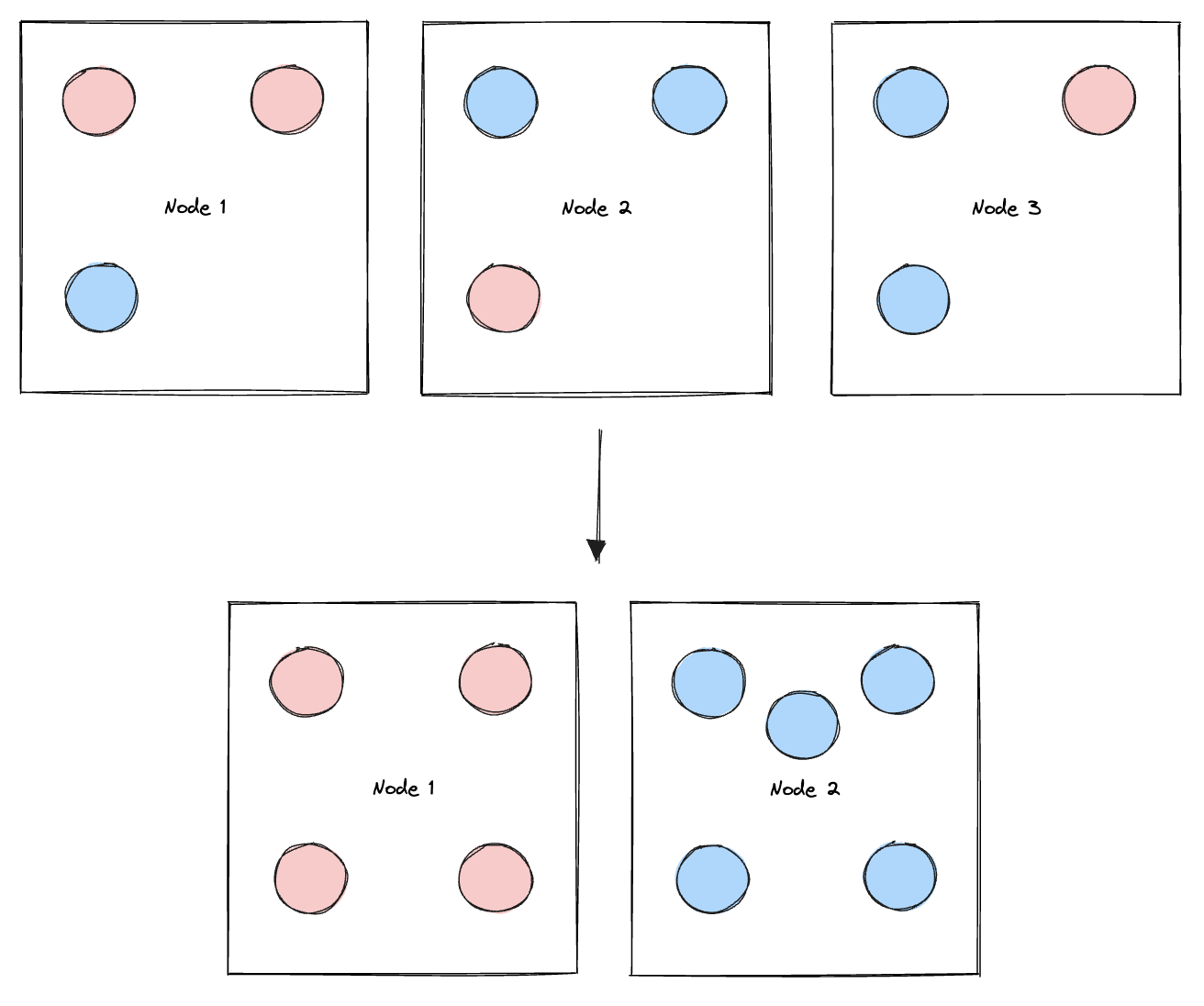
Snorkel nutzte die Kubernetes-Ressource podAffinities, um dieses Problem zu beheben. Damit konnten sie einschränken, auf welchen Knoten ein Pod ausgeführt werden kann, basierend auf den Labels anderer Pods, die bereits auf einem bestimmten Knoten laufen. Sie fügten den Pods Labels hinzu, um zwischen festen und flexiblen Pods zu unterscheiden und fügten ihrer Bereitstellungskonfiguration eine podAntiAffinity hinzu, um sicherzustellen, dass feste Pods nicht auf Knoten geplant werden, auf denen flexible Pods ausgeführt werden, und umgekehrt.
Diese Implementierung von podAffinities ermöglichte es Snorkel AI, Knoten in zwei funktionale Gruppen aufzuteilen: die feste Gruppe von Knoten, die feste Pods enthalten, die niemals sicher zwischen Knoten verschoben werden können (z. B. Redis aufgrund des Caches), und die flexible Gruppe von Knoten, die „flexible“ Pods enthält, die entweder kurzlebig sind (wie Worker-Pods) oder außerhalb der Geschäftszeiten (z. B. über Nacht) sicher bewegt werden können.
Obwohl dies mit manuellem Eingreifen bei der Plattformwartung möglich ist, kann Snorkel die festen Knoten nicht automatisch herunterskalieren. Diese Lösung ermöglicht es ihnen jedoch, die flexiblen Knoten automatisch herunterzuskalieren, da sie nun die unbeweglichen Pods in die festen Knoten isoliert haben.
Fazit
Die Teams von Snorkel und AWS Startups hoffen, dass das Teilen dieses Denkprozesses und dieser Lösungen anderen Startups hilft, eine bessere Infrastruktur für ML-Workloads aufzubauen, die schnell an Bedeutung gewinnen, da ML, große Sprachmodelle und andere FMs ihren Weg in die Produktion für Unternehmen auf der ganzen Welt finden.
Nehmen Sie an der AWS re:Invent 2023 teil? Diese Bereitstellung wird im Rahmen der Snorkel-Sitzung Navigieren durch die Zukunft der KI: Bereitstellung von generativen Modellen auf Amazon EKS (Sitzung CON312) vorgestellt. Schauen Sie sich das auf jeden Fall an!
Vielen Dank an David Hao, Edmond Liu und Alec Xiang, die dazu beigetragen haben, diese technische Vision für Snorkel Wirklichkeit werden zu lassen. Besonderer Dank gilt den oben Genannten sowie Matt Casey, Henry Ehrenberg, Anthony Bishopric und dem gesamten Snorkel-Infrastrukturentwicklungsteam für ihr aufmerksames Feedback zu diesem Artikel.

Ganapathi Krishnamoorthi
Ganapathi Krishnamoorthi ist Senior ML Solutions Architect bei AWS. Ganapathi bietet Startup- und Unternehmenskunden präskriptive Anleitungen und hilft ihnen dabei, Cloud-Anwendungen in großem Maßstab zu entwickeln und bereitzustellen. Er ist auf Machine Learning spezialisiert und konzentriert sich darauf, Kunden dabei zu helfen, KI/ML für ihre Geschäftsergebnisse zu nutzen. Wenn er nicht auf der Arbeit ist, erkundet er gerne die Natur und hört Musik.
Wie war dieser Inhalt?