Comment a été ce contenu ?
ApprendreCoup de projecteur : Datagen crée des données synthétiques de haute fidélité pour résoudre des problèmes centrés sur l'homme
Coup de projecteur : Datagen crée des données synthétiques de haute fidélité pour résoudre des problèmes centrés sur l'homme
Lorsque Gil Elbaz et Ofir Zuk ont fondé Datagen en 2018, c'était dans le but de réinventer le processus défaillant qui permet aux clients d'obtenir des données pour la formation sur les réseaux de reconnaissance d'image. Plus précisément, ils souhaitaient apporter la simulation de données à chaque équipe de reconnaissance d'image de manière continue et évolutive.

Comme les performances des modèles d'IA dépendent à la fois de la qualité du modèle et de la qualité des données utilisées pour l'entraîner, il est essentiel de disposer d'une grande quantité de données fiables, et il est souvent difficile d'en collecter autant que nécessaire. Les données du monde réel ont également tendance à poser problème en termes de rapidité d'acquisition, de précision, de coût et de biais. « Une personne collectera des données [réelles] concernant différentes identités, par exemple, des visages, mais elle ne collectera pas assez de données sur certaines ethnies, certains âges ou certains sexes », explique Shay Navon, directeur principal du marketing produit chez Datagen. « Du coup, vous obtenez ce biais. »
Afin d'aider les équipes de reconnaissance d'image à lutter contre les biais, Datagen propose un moyen unique de générer des données à l'aide d'algorithmes informatiques. Leurs données synthétiques s'apparentent à des données du monde réel à la fois statistiquement et mathématiquement, mais peuvent être générées rapidement, à moindre coût, et sont exemptes d'erreur humaine. Au lieu de confier à un être humain la corvée de recueillir et d'annoter les données manuellement, tâche qui demande beaucoup de travail et qui nécessite de prendre une photo d'un visage puis d'étiqueter ses traits à la main, les données synthétiques sont générées à grande échelle, avec des annotations de base intégrées, telles que la direction des yeux, qu'il serait impossible pour un humain de déterminer. Il en résulte une annotation des données plus précise et plus détaillée, sans le défi du balisage manuel.
« Nous simulons le monde pour accélérer la mise en production de l'IA », explique Karine Regev, vice-présidente du marketing chez Datagen. « La mise en production de l'IA constitue en soi un défi non résolu pour la plupart des entreprises. C'est pourquoi nous la rendons plus professionnelle, plus précise, en résolvant des problèmes tels que la confidentialité, les biais dans les données, qui constituent les principaux obstacles de l'IA moderne. »
Datagen propose à ses clients une plateforme en libre-service qui utilise des simulations 3D pour entraîner leurs algorithmes. « Pour entraîner un modèle, vous avez besoin de millions d'images différentes », explique Mme Regev. « Et c'est exactement là que nous nous situons. [Les clients de Datagen] ont la possibilité de contrôler les scènes, l'arrière-plan, les différentes modalités, les différentes étiquettes dont vous avez besoin, l'éclairage, le sexe, l'origine ethnique, etc. »
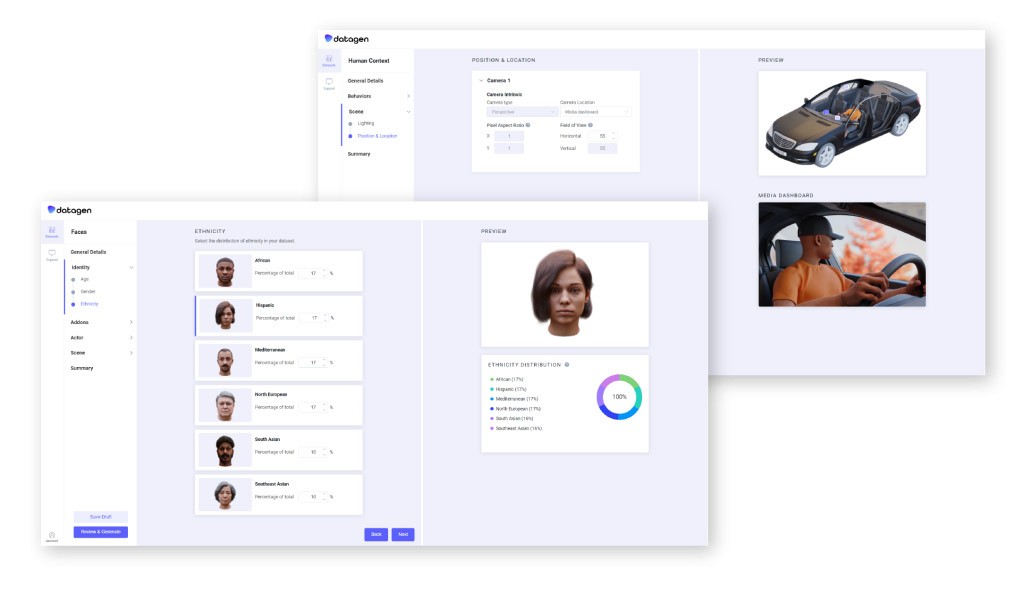
En plus de générer diverses données qui semblent réelles, évolutives et parfaites au pixel près, Datagen offre à ses clients une confidentialité totale. « C'est totalement conforme à la confidentialité, car les données ne contiennent aucune information personnelle identifiable », explique Shay Navon à propos des données synthétiques. « Personne ne peut dire : 'C'est quelqu'un que nous utilisons qui pose un problème de confidentialité'. Notre expertise et nos données centrées sur l'humain se concentrent sur plusieurs domaines, de la détection des repères faciaux à l'estimation du regard et l'analyse de l'expression aux poses complètes du corps humain, aux parties du corps telles que les yeux, les mains, etc. »
Dans un avenir très proche, on prévoit qu'il sera plus courant d'entraîner des modèles à partir de données synthétiques que de les collecter à partir de sources réelles. En conséquence, Datagen a connu une croissance rapide, passant d'une quarantaine d'employés à près de 100 au cours des neuf derniers mois. « Nous travaillons avec certaines des plus grandes entreprises de technologies du monde dans différents secteurs verticaux », explique Mme Regev. « Résolution de différents cas d'utilisation, allant de la réalité augmentée, de la réalité virtuelle et du métaverse à la surveillance du conducteur pour les véhicules automobiles en cabine, en passant par la sécurité domestique et les bureaux intelligents. »

Afin de répondre à cette nouvelle demande, Datagen a décidé de passer à une architecture cloud. Sa priorité était d'évoluer en utilisant les derniers modèles de GPU. Après une analyse approfondie des fournisseurs de cloud, elle s'est tournée vers AWS, déterminée à développer son système sur Kubernetes. Datagen a conçu un système logiciel de planification personnalisé appelé Agni qui s'intègre à Elastic Kubernetes Service (Amazon EKS) et utilise l'autoscaling de Kubernetes et les groupes AWS Auto Scaling.
Agni, comme l'ensemble de la plateforme de génération de données de Datagen, s'appuie désormais sur des instances spot de CPU et de GPU, ce qui lui a permis de réduire ses coûts et de créer un système plus efficace. Cela lui permet également de gérer un système relativement petit qui peut croître de manière dynamique jusqu'à des centaines de milliers d'emplois simultanés et se réduire à la demande, ce qui se traduit par une plateforme en libre-service hébergée par AWS.
À l'avenir, l'équipe de Datagen prévoit que le besoin en données synthétiques continuera de croître. « Nous sommes confrontés à une forte demande, tant en termes de traction que de perspectives, un besoin de leadership éclairé, un besoin de technologie et d'une solution comme la nôtre capable de mener la conversation en matière de données synthétiques », explique Mme Regev.

AWS Editorial Team
L'équipe de marketing de contenu d'AWS Startups collabore avec des startups de toutes tailles et de tous secteurs pour proposer un contenu exceptionnel qui éduque, divertit et inspire.
Comment a été ce contenu ?