為何選擇 SageMaker Data Wrangler?
Amazon SageMaker Data Wrangler 將表格、影像和文字資料的資料準備時間從數週縮短至幾分鐘。使用 SageMaker Data Wrangler,您可以透過視覺化和自然語言介面來簡化資料準備和特徵工程。使用 SQL 和 300 多個內建轉換,快速選取、匯入和轉換資料,而無需編寫程式碼。產生直覺化的資料品質報告,以偵測各種資料類型的異常情況,並估算模型效能。擴展以處理 PB 級資料。
SageMaker Data Wrangler 的優勢
運作方式
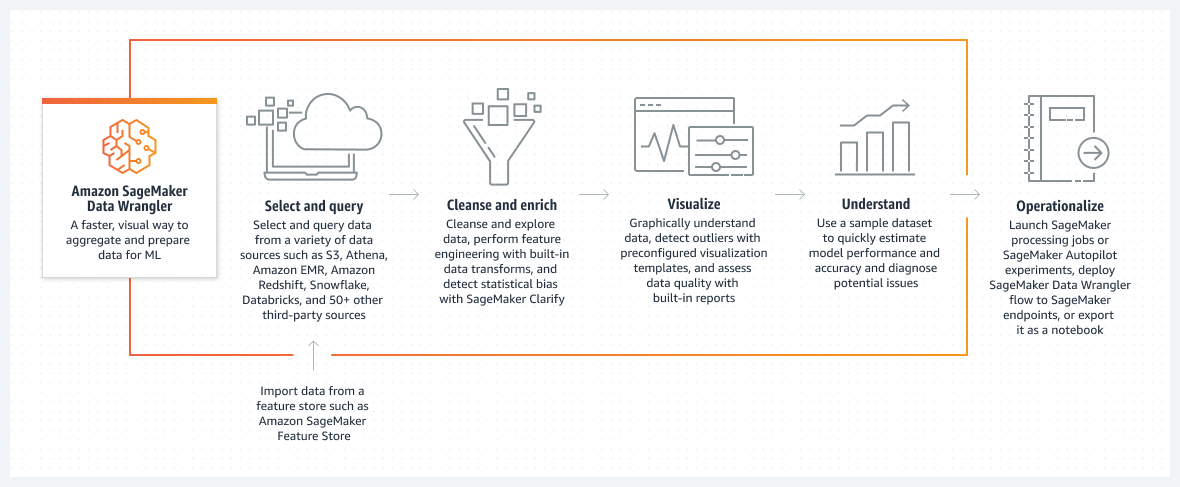
運作方式

標題 1︰Amazon SageMaker Data Wrangler
描述文字︰以一種更快捷、更直觀的方式來為機器學習彙總和準備資料
標題 2:選取和查詢
描述文字:從各種資料來源中選取和查詢資料,例如 Amazon S3、Athena、Amazon EMR、Amazon Redshift、Snowflake、Databricks 和 50 多個其他第三方來源
子描述:從 Amazon SageMaker Feature Store 等特徵存放區匯入資料
標題 3:清理和充實
描述文字:清理和探索資料,使用內建資料轉換執行特徵工程,並使用 Amazon SageMaker Clarify 偵測統計偏差
標題 4:視覺化
描述文字:以圖形方式了解資料,使用預先設定的視覺化範本偵測極端值,並使用內建報告評估資料品質
標題 5︰了解
描述文字:使用範例資料集快速評估模型效能和準確性,並診斷潛在問題
標題 6:操作化
描述文字:啟動 Amazon SageMaker 處理任務或 Amazon SageMaker Autopilot 實驗,將 Amazon SageMaker Data Wrangler 流程部署至 Amazon SageMaker 端點,或將其匯出為筆記本。
加速存取、選取和查詢資料
藉助 SageMaker 資料管理程式,您可以快速存取 S3、Athena、Redshift 以及 50 多個第三方來源等 Amazon 服務的表格、文字和影像資料。您可以使用視覺化查詢建置器選取資料、編寫 SQL 查詢,或直接以各種格式 (例如 CSV 和 Parquet) 匯入資料資料。

產生資料洞察並了解資料品質
Amazon SageMaker Data Wrangler 提供資料品質和洞察報告,自動驗證資料品質 (如缺失值、重複行和資料類型),並幫助偵測資料中的異常狀況 (如極端值、類別不平衡和資料洩漏)。一旦可以有效地驗證資料品質,您就可以快速運用領域知識來處理資料集,以進行 ML 模型訓練。

透過視覺化來了解資料
SageMaker Data Wrangler 透過強大的內建視覺化範本,例如直方圖、散射圖、特徵重要性和關聯性等,協助您了解資料。憑藉直覺化資料品質報告,偵測不同資料類型的異常狀況,並提供建議以改善資料品質,以加速資料探索。

更高效地轉換資料
SageMaker Data Wrangler 提供超過 300 種預建的 PySpark 轉換和自然語言介面,無需編碼即可準備表格、時間序列、文字和影像資料。包括向量化文字、特徵化日期時間、編碼、平衡資料或影像增強等常見使用案例。您還可以在 PySpark、SQL 和 Pandas 中編寫自訂轉換,或使用自然語言介面來產生程式碼。內建程式碼片段程式庫可簡化自訂轉換的編寫。

了解資料的預測能力
SageMaker Data Wrangler 提供 Quick Model 分析,以估計資料的預測能力。您可以了解估計的模型準確度、特徵重要性以及混亂矩陣,以協助您在訓練模型之前驗證資料品質。

自動化和部署 ML 資料準備工作流程
SageMaker Data Wrangler 可讓您進行擴展以為 PB 級資料做準備,而無需進行 PySpark 編碼或啟動叢集。直接從 UI 啟動處理任務,或將資料匯出至 SageMaker 特徵存放區或與 SageMaker Pipelines 整合,藉此將資料準備整合至 ML 工作流程中。您還可以將資料流程匯出為 Jupyter 筆記本或 Python 指令碼,以程式設計方式複寫資料準備步驟。

客戶
「在 Invista,我們以轉型為動力,並致力於開發造福全球客戶的產品和技術。我們將 ML 視為改善客戶體驗的一種方式。但是,面對包含數億列資料的資料集,我們需要一個解決方案來幫助我們準備資料,以及大規模開發、部署和管理 ML 模型。藉助 Amazon SageMaker Data Wrangler,我們現在可以有效地以互動方式選取、清除、探索和了解我們的資料,讓我們的資料科學團隊能夠建立特徵工程管道,輕鬆地擴展至跨越數億列的資料集。透過 Amazon SageMaker Data Wrangler,我們可以更快地操作 ML 工作流程。」
Invista 前首席資料科學家 Caleb Wilkinson
「藉助 ML,3M 正在改進久經考驗的產品,如砂紙,並推動其他幾個領域的創新,包括醫療保健領域。當我們計劃將 ML 擴展到 3M 的更多領域時,我們看到資料和模型的數量正在迅速增長 – 每年都翻一番。我們對 SageMaker 的新功能充滿期待,因為這些功能能夠協助我們擴展。Amazon SageMaker Data Wrangler 使準備資料以進行模型訓練變得容易許多,而且透過利用 Amazon SageMaker Feature Store,我們再也不需要反复建立相同的模型特徵。最後,Amazon SageMaker Pipelines 將協助我們將資料準備、模型建置和模型部署整合到端到端工作流程中,實現自動化,從而讓我們加快模型的上市速度。我們的研究人員期待利用 3M 的新科學速度。」
3M Corporate Systems Research Lab 前技術總監 David Frazee
「Amazon SageMaker Data Wrangler 使我們能夠透過一系列豐富的轉換工具快速滿足我們的資料準備需求。這些轉換工具可加速 ML 資料準備程序,從而加快新產品推向市場的速度。我們的客戶受益於我們擴展部署模型的速度。我們能夠在幾天而不是幾個月內提供可衡量的永續結果,滿足客戶的需求。」
Deloitte 首席合夥人兼人工智慧生態系統和平台主管 Frank Farrall
「作為 AWS 核心級諮詢合作夥伴,我們的工程團隊正在與 AWS 密切合作以建置創新解決方案,來協助我們的客戶不斷提高其營運效率。ML 是我們創新解決方案的核心,但我們的資料準備工作流程涉及複雜的資料準備技術,因此需要花費大量時間才能在生產環境中進行實作。借助 Amazon SageMaker Data Wrangler,我們的資料科學家可以完成資料準備工作流程的每個步驟,包括資料選取、清理、探索和視覺化,這有助於我們加快資料準備程序,並輕鬆準備用於 ML 的資料。藉助 Amazon SageMaker Data Wrangler,我們可以更快地為 ML 準備資料。」
NRI 日本公司資深常務董事 Shigekazu Ohmoto
「隨著我們在人口健康管理市場的足跡涉及更多的醫療支付方、提供者、藥房福利管理者和其他醫療保健組織,我們需要一種解決方案來自動化資料來源的端到端處理程序,這些資料來源為我們的 ML 模型餽送資料,包括索賠資料、註冊資料和藥房資料。藉助 Amazon SageMaker Data Wrangler,我們現在可以使用一組更易於驗證和重複使用的工作流程,來加快 ML 的資料彙總和準備速度。這讓我們極大地縮短了模型的交付時間和品質,提高了資料科學家的效率,並將資料準備時間縮短了近 50%。此外,SageMaker Data Wrangler 協助我們節省了多次 ML 反覆運作和大量的 GPU 時間,加快了我們客戶的整個端到端程序,因為我們現在可以建置具有數千種特徵的資料市集,這些特徵包括藥房、診斷碼、急診室就診、住院以及人口和其他社會決定因素。借助 SageMaker Data Wrangler,我們可以高效地轉換資料以建置訓練資料集,在執行 ML 模型之前產生對資料集的資料洞察,並為推論/預測準備大規模的真實資料。」
Equilibrium Point IoT 執行長 Lucas Merrow