Amazon SageMaker モデルトレーニングとは
Amazon SageMaker Training では、インフラストラクチャを管理する必要なく、大規模な機械学習 (ML) モデルのトレーニングとチューニングにかかる時間とコストを削減できます。現在使用可能な極めて高い性能の ML コンピューティングインフラストラクチャを利用でき、Amazon SageMaker AI はインフラストラクチャを 1 から数千の GPU まで自動的にスケールアップまたはスケールダウンできます。深層学習モデルをより迅速にトレーニングできるよう、SageMaker AI はお客様がリアルタイムでデータセットを選択および改善するのをサポートします。SageMaker の分散トレーニングライブラリは、大規模モデルとトレーニングデータセットを AWS GPU インスタンス間で自動的に分割できます。また、DeepSpeed、Horovod、Megatron などのサードパーティーライブラリを使用することもできます。トレーニングクラスターを自動的にモニタリングおよび修復することで、数週間から数か月間にわたって中断することなく、基盤モデル (FM) をトレーニングできます。
費用対効果の高いトレーニングのメリット
モデルを大規模にトレーニング
フルマネージドトレーニングジョブ
SageMaker トレーニングジョブは、大規模な分散 FM トレーニングのためにフルマネージドユーザーエクスペリエンスを提供することで、インフラストラクチャ管理に関する差別化につながらない手間のかかる作業を排除します。SageMaker トレーニングジョブは、レジリエントな分散トレーニングクラスターの自動スピンアップ、インフラストラクチャの監視、および障害からの自動回復を行って、スムーズなトレーニングエクスペリエンスを確保します。トレーニングが完了すると、SageMaker がクラスターをスピンダウンし、トレーニングの正味時間分の料金が請求されます。さらに、SageMaker トレーニングジョブには個々のワークロードに合わせて最適なインスタンスタイプを選択する柔軟性があり (例: P5 クラスターでの大規模言語モデル (LLM) の事前トレーニングや、p4d インスタンスでのオープンソース LLM のファインチューニングなど)、トレーニング予算をさらに最適化できます。さらに、SagerMaker トレーニングジョブは、さまざまなレベルの技術的専門知識とさまざまなワークロードタイプを有する ML チーム全体に、一貫したユーザーエクスペリエンスを提供します。
SageMaker HyperPod
Amazon SageMaker HyperPod は、コンピューティングクラスターを効率的に管理して基盤モデル (FM) の開発をスケールするための専用インフラストラクチャです。このインフラストラクチャは、高度なモデルトレーニング手法、インフラストラクチャ制御、パフォーマンス最適化、強化されたモデルオブザーバビリティを実現します。Amazon SageMaker HyperPod は SageMaker 分散トレーニングライブラリで事前設定されているため、モデルとトレーニングデータセットを AWS クラスターインスタンス全体で自動的に分割して、クラスターのコンピューティングおよびネットワークインフラストラクチャの効率的な活用に役立てることができます。SageMaker HyperPod は、ハードウェア障害の検出、診断、および回復を自動的に実行してよりレジリエントなトレーニング環境を実現することで、FM のトレーニングを中断することなく数か月間継続し、トレーニング時間を最大 40% 短縮します。
高性能分散型トレーニング
SageMaker AI は、モデルとトレーニングデータセットを AWS アクセラレーター間で自動的に分割することで、分散トレーニングをより迅速に実行できるようにします。 AWS ネットワークインフラストラクチャとクラスタートポロジ向けにトレーニングジョブを最適化するのに役立ちます。また、チェックポイントの保存頻度を最適化することでレシピを通じてモデルチェックポイントを合理化し、トレーニング中のオーバーヘッドが最小限に抑えられるようにします。レシピを使用すると、あらゆるスキルセットのデータサイエンティストやデベロッパーは、最新のパフォーマンスの恩恵を受けながら、Llama 3.1 405B、Mixtral 8x22B、Mistral 7B などの公開されている生成 AI モデルのトレーニングとファインチューニングをすぐに開始できます。レシピには、AWS によってテストされたトレーニングスタックが含まれています。これにより、さまざまなモデル設定をテストする何週間もの煩雑な作業が不要になります。1 行のレシピ変更で GPU ベースのインスタンスと AWS Trainium ベースのインスタンスを切り替え、トレーニングの回復力を高めるために自動モデルチェックポイントを有効にすることができます。さらに、任意の SageMaker トレーニング機能を使用して、本番でワークロードを実行できます。
インタラクティビティとモニタリングのためのビルトインツール
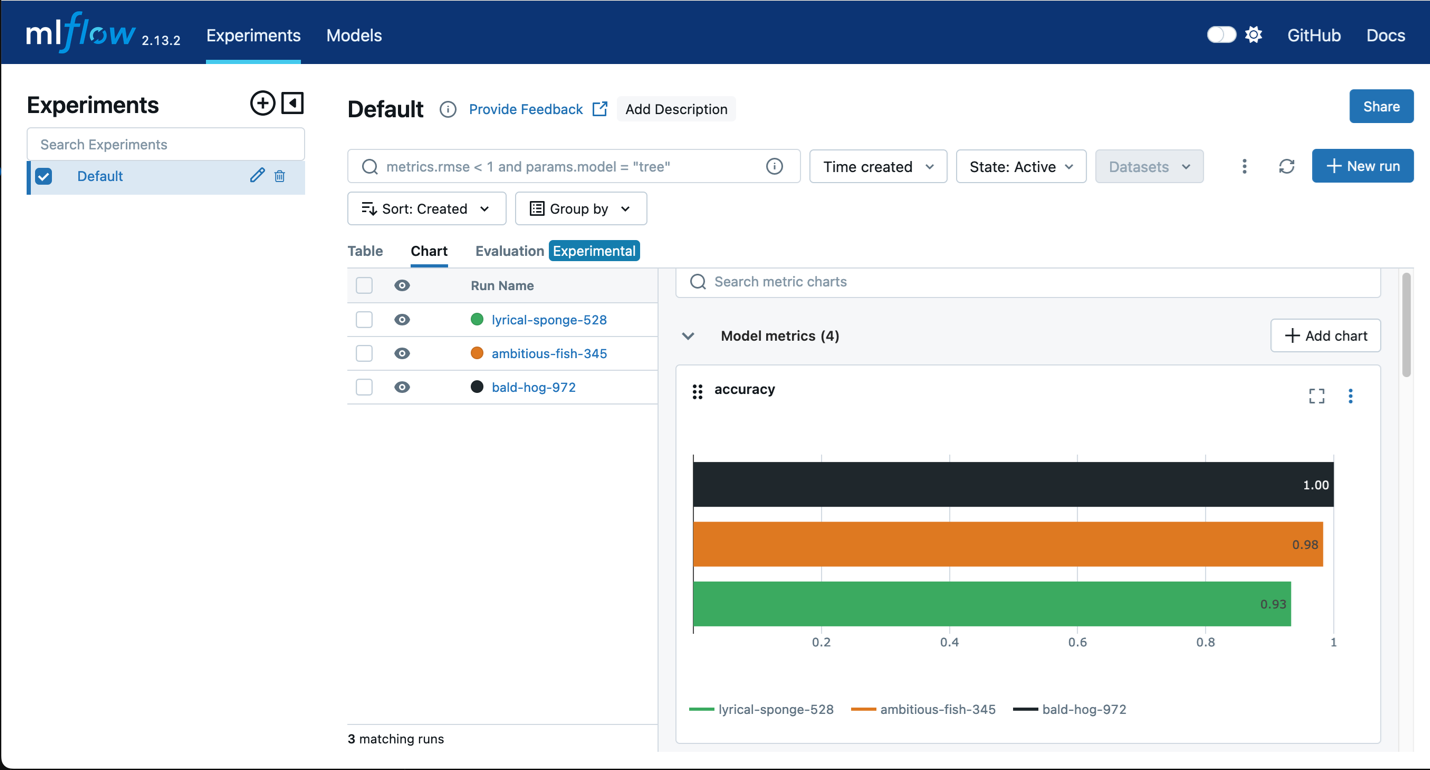
Amazon SageMaker と MLflow
MLflow を SageMaker トレーニングと併用して、入力パラメータ、設定、結果を取得することで、お客様のユースケースに最適なパフォーマンスを発揮するモデルを迅速に特定できます。MLflow UI を使用すると、モデルトレーニングの試行を分析し、本番用の候補モデルを 1 つの簡単なステップで簡単に登録できます。
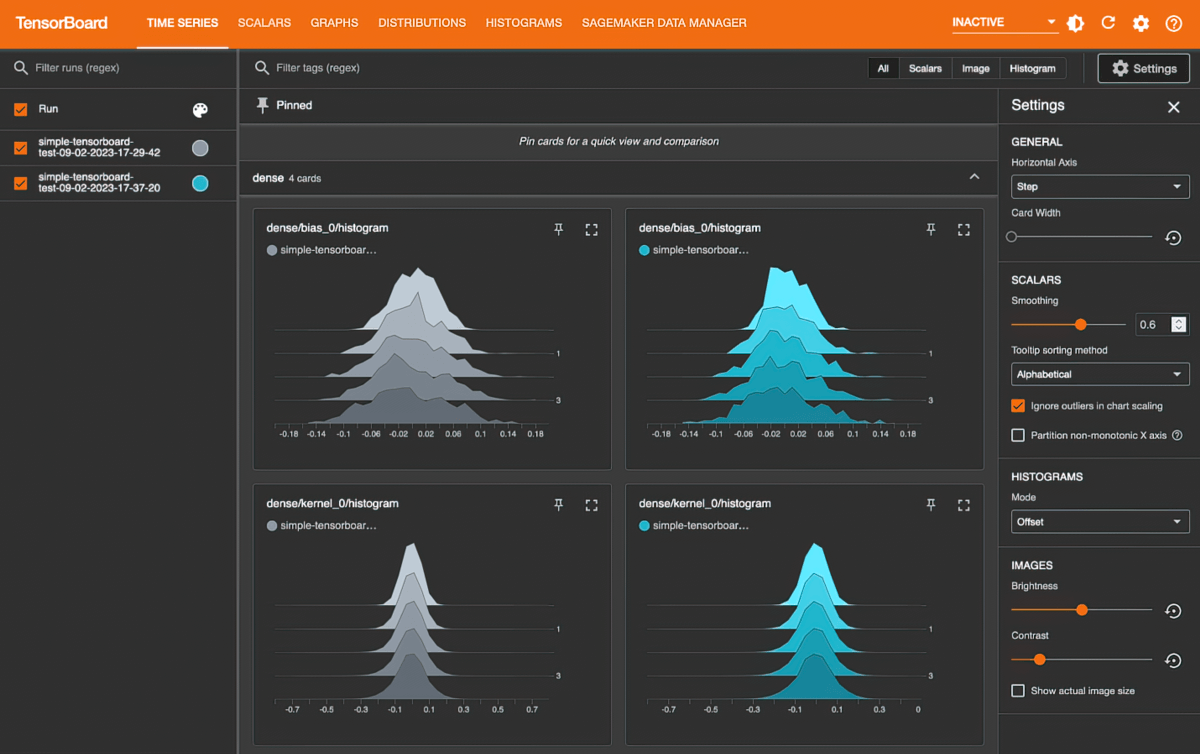
Amazon SageMaker with TensorBoard
Amazon SageMaker with TensorBoard は、検証損失が収束しない、勾配が消えるなどの収束の問題を特定し修正するために、モデルアーキテクチャを可視化することで、開発時間を節約するのに役立ちます。