Amazon SageMaker Data Wrangler
Il modo più facile e veloce per preparare dati per il machine learning, ora disponibile su SageMaker CanvasPerché scegliere SageMaker Data Wrangler?
Amazon SageMaker Data Wrangler riduce i tempi di preparazione di dati tabulari, immagini e testi da settimane a minuti. Inoltre, semplifica la preparazione dei dati e l'ingegneria delle caratteristiche tramite un'interfaccia visiva e in linguaggio naturale. Seleziona, importa e trasforma rapidamente dati con SQL e oltre 300 trasformazioni integrate senza scrivere codice. Crea report intuitivi sulla qualità dei dati per individuare anomalie tra i tipi di dati e stimare le prestazioni del modello. Scala per elaborare petabyte di dati.
Vantaggi di SageMaker Data Wrangler
Come funziona
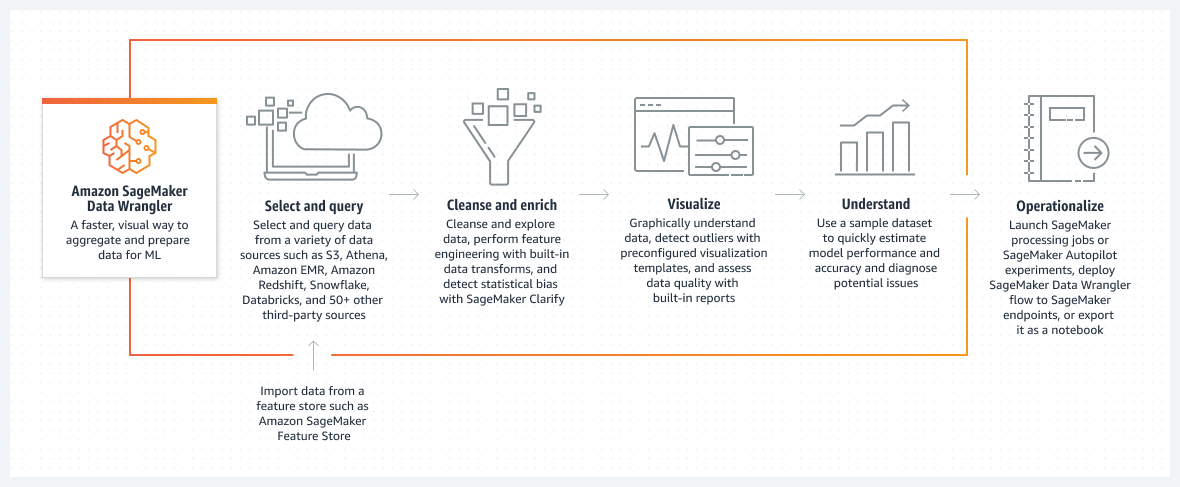
Come funziona

Titolo 1: Amazon SageMaker Data Wrangler
Testo di descrizione: Un modo visivo e più veloce per aggregare e preparare i dati per il ML
Titolo 2: Selezione ed esecuzione di query
Testo di descrizione: Seleziona i dati ed esegui query da una varietà di origini dati, quali Amazon S3, Athena, Amazon EMR, Amazon Redshift, Snowflake, Databricks e più di 50 altre origini di terze parti
Descrizione secondaria: Importa i dati da un feature store come Amazon SageMaker Feature Store
Titolo 3: Pulizia e arricchimento
Testo di descrizione: Pulisci i dati e ricavane informazioni, esegui attività di ingegneria delle funzionalità con le trasformazioni dei dati predefinite e rileva le distorsioni statistiche con SageMaker Clarify
Titolo 4: Visualizzazione
Testo di descrizione: Comprendi visivamente i dati, rileva i valori anomali con i modelli di visualizzazione preconfigurati e valuta la qualità dei dati con i report predefiniti
Titolo 5: Comprensione
Testo di descrizione: Utilizza un set di dati campione per stimare rapidamente le prestazioni e la precisione del modello e per rilevare i possibili problemi
Titolo 6: Operazionalizzazione
Testo di descrizione: Avvia processi di elaborazione SageMaker o esperimenti del pilota automatico SageMaker, implementa i flussi SageMaker Data Wrangler negli endpoint SageMaker o esportali sotto forma di notebook.
Velocità più elevata di accesso, selezione ed esecuzione di query sui dati
Con SageMaker Data Wrangler, vengono effettuati accessi rapidi a dati tabulari, di testo e di immagini da servizi Amazon come S3, Athena, Redshift e oltre 50 fonti di terze parti. È possibile selezionare i dati con builder di query visive, scrivere query SQL o importare i dati direttamente in vari formati come CSV e Parquet.

Genera approfondimenti sui dati e comprendi la qualità dei dati
SageMaker Data Wrangler fornisce un report sulla qualità dei dati e relativi approfondimenti che verifica in automatico la qualità dei dati (ad esempio valori mancanti, righe duplicate e tipi di dati) e contribuisce a rilevare le anomalie (come valori anomali, squilibri di classe e perdita di dati) al loro interno. Una volta che sei in grado di verificare efficacemente la qualità dei dati, puoi applicare rapidamente la conoscenza del dominio per elaborare set di dati per l'addestramento dei modelli di ML.

Comprensione visiva dei dati con le visualizzazioni
SageMaker Data Wrangler aiuta a comprendere i dati attraverso robusti modelli di visualizzazione integrati come istogrammi, grafici a dispersione, importanza delle funzionalità e correlazioni. Accelera l'esplorazione dei dati con report intuitivi sulla qualità dei dati che rilevano le anomalie tra tipi di dati e forniscono suggerimenti per migliorare la qualità dei dati.

Trasformazione dei dati più efficace
SageMaker Data Wrangler offre oltre 300 trasformazioni PySpark predefinite e un'interfaccia in linguaggio naturale per preparare dati tabulari, di serie temporali, di testo e di immagini senza codifica, coprendo i casi d'uso più comuni come la vettorializzazione di testo, la caratterizzazione della data e dell'ora, la codifica, il bilanciamento dei dati o l'aumento delle immagini. È possibile, inoltre, creare trasformazioni personalizzate in PySpark, SQL e Pandas oppure usare l'interfaccia in linguaggio naturale per generare codice. Una libreria integrata di frammenti di codice semplifica la scrittura di trasformazioni personalizzate.

Comprensione del potere predittivo dei dati
SageMaker Data Wrangler fornisce un'analisi del Quick Model per stimare il potere predittivo dei dati. Ne consegue una stima della precisione del modello, dell'importanza delle funzionalità e una matrice di confusione che aiuta a convalidare la qualità dei dati prima di addestrare i modelli.

Automazione e implementazione dei flussi di lavoro di preparazione dei dati di ML
SageMaker Data Wrangler consente di scalare per preparare petabyte di dati senza codificare PySpark o far girare i cluster. È possibile avviare i lavori di elaborazione direttamente dall'interfaccia utente o integrare la preparazione dei dati nei flussi di lavoro di ML esportando i dati in SageMaker Feature Store o integrandoli con SageMaker Pipelines. È anche possibile esportare i flussi di dati come notebook Jupyter o script Python per la replica programmatica delle fasi di preparazione dei dati.

Clienti
"Noi di INVISTA siamo guidati dalla trasformazione e cerchiamo di sviluppare prodotti e tecnologie a vantaggio dei clienti di tutto il mondo. Vediamo il machine learning come un modo per migliorare l'esperienza del cliente. Tuttavia, con set di dati che si estendono su centinaia di milioni di righe, avevamo bisogno di una soluzione che ci aiutasse a preparare i dati e sviluppare, implementare e gestire modelli di machine learning su larga scala. Con Amazon SageMaker Data Wrangler, ora possiamo selezionare, pulire, esplorare e comprendere i nostri dati in modo interattivo, consentendo al nostro team di data science di creare pipeline di progettazione delle funzionalità che possono essere scalate facilmente su set di dati che si estendono su centinaia di milioni di righe. Con Amazon SageMaker Data Wrangler, possiamo rendere operativi i nostri flussi di lavoro ML più velocemente".
Caleb Wilkinson, Former Lead Data Scientist, INVISTA
"Grazie al ML, 3M sta migliorando prodotti collaudati, come la carta vetrata, e sta promuovendo l'innovazione in molti altri settori, incluso quello sanitario. Mentre progettiamo di scalare il machine learning in più aree di 3M, vediamo la quantità di dati e modelli crescere rapidamente: raddoppiano ogni anno. Siamo entusiasti delle nuove caratteristiche di SageMaker perché ci aiutano a dimensionare le risorse. Amazon SageMaker Data Wrangler facilita notevolmente la preparazione dei dati per l'addestramento del modello e Amazon SageMaker Feature Store eliminerà la necessità di creare le stesse caratteristiche del modello più e più volte. Infine, Pipeline Amazon SageMaker ci aiuterà ad automatizzare la preparazione dei dati, la creazione del modello e l'implementazione del modello in un flusso di lavoro end-to-end in modo da poter accelerare il time-to-market dei nostri modelli. I nostri ricercatori non vedono l'ora di sfruttare la nuova velocità della scienza in 3M".
David Frazee, Former Technical Director, 3M Corporate Systems Research Lab
"Amazon SageMaker Data Wrangler ci permette di partire in quarta nell'affrontare le nostre esigenze di preparazione dei dati con una ricca collezione di strumenti di trasformazione che accelerano il processo di preparazione dei dati di machine learning necessari per portare nuovi prodotti sul mercato. A loro volta, i nostri clienti traggono vantaggio dalla velocità con cui dimensioniamo i modelli implementati che ci permettono di offrire risultati misurabili e sostenibili che soddisfano le esigenze dei nostri clienti in pochi giorni piuttosto che in mesi".
Frank Farrall, Principal, AI Ecosystems and Platforms Leader, Deloitte
"In qualità di partner di consulenza Premier AWS, i nostri team tecnici stanno lavorando a stretto contatto con AWS per sviluppare soluzioni innovative per aiutare i nostri clienti a migliorare continuamente l'efficienza delle loro operazioni. Il machine learning è il cuore delle nostre soluzioni innovative, ma il nostro flusso di lavoro di preparazione dei dati comporta tecniche sofisticate che, di conseguenza, richiedono una quantità significativa di tempo per essere rese operative in un ambiente di produzione. Con Amazon SageMaker Data Wrangler, i nostri data scientist possono completare ogni fase del flusso di lavoro di preparazione dei dati, compresa la selezione, la pulizia, l'esplorazione e la visualizzazione, il che ci aiuta ad accelerare il processo di preparazione dei dati e a preparare facilmente i nostri dati per il machine learning. Con Amazon SageMaker Data Wrangler possiamo preparare più velocemente i dati per il machine learning".
Shigekazu Ohmoto, Senior Corporate Managing Director, NRI Japan
"Poiché la nostra impronta nel mercato della gestione della salute della popolazione continua ad espandersi in un maggior numero di pagatori sanitari, fornitori, gestori di prestazioni farmaceutiche e altre organizzazioni sanitarie, avevamo bisogno di una soluzione per automatizzare i processi end-to-end per le origini dei dati che alimentano i nostri modelli di machine learning, compresi i dati di richieste, registrazione e delle farmacie. Ora con Amazon SageMaker Data Wrangler possiamo ridurre il tempo necessario per l'aggregazione e la preparazione dei dati per il machine learning tramite una serie di flussi di lavoro che sono più facili da convalidare e riutilizzare. In questo modo abbiamo migliorato notevolmente il tempo di consegna e la qualità dei nostri modelli, aumentato l'efficacia dei nostri data scientist e ridotto il tempo di preparazione dei dati di quasi il 50%. Inoltre, SageMaker Data Wrangler ci ha aiutato a risparmiare più iterazioni di machine learning e un tempo significativo di GPU, accelerando l'intero processo end-to-end per i nostri clienti, dato che ora possiamo creare data mart con migliaia di caratteristiche tra cui farmacia, codici di diagnosi, visite di pronto soccorso, degenze ospedaliere, demografia e altri determinanti sociali. Con SageMaker Data Wrangler, possiamo trasformare i nostri dati con una maggiore efficienza per la creazione di set di dati di addestramento, generare informazioni dettagliate sui set di dati prima di eseguire modelli di machine learning e preparare i dati del mondo reale per inferenze/previsioni su larga scala".
Lucas Merrow, CEO, Equilibrium Point IoT
Nozioni di base su SageMaker Data Wrangler
Blog
Video
AWS re:Invent 2023: Democratizza il ML senza codice o a basso codice utilizzando Amazon SageMaker Canvas (AIM217)
AWS re:Invent 2023: Nuove funzionalità LLM in Amazon SageMaker Canvas, con Bain & Company (AIM363)
Novità
- Data (dalla più alla meno recente)