Amazon SageMaker Data Wrangler
Le moyen le plus rapide et le plus facile de préparer des données pour le machine learning – maintenant dans SageMaker Canvas
Pourquoi SageMaker Data Wrangler ?
Amazon SageMaker Data Wrangler réduit le temps de préparation des données tabulaires, d’images et textuelles de plusieurs semaines à quelques minutes. Avec SageMaker Data Wrangler, vous pouvez simplifier la préparation des données et l’ingénierie des fonctionnalités grâce à une interface visuelle et en langage naturel. Sélectionnez, importez et transformez rapidement des données avec SQL et plus de 300 transformations intégrées sans écrire de code. Générez des rapports intuitifs sur la qualité des données afin de détecter les anomalies dans tous les types de données et d’estimer les performances des modèles. Effectuez une mise à l’échelle pour traiter des pétaoctets de données.
Avantages de SageMaker Data Wrangler
Fonctionnement
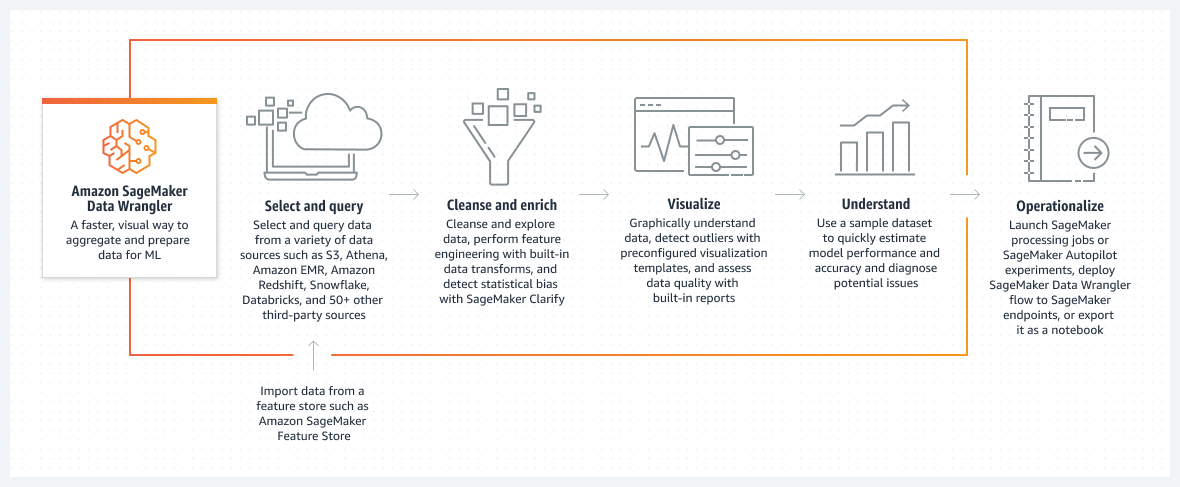
Fonctionnement

Titre 1 : Amazon SageMaker Data Wrangler
Texte de description : un moyen plus rapide et visuel d'agréger et de préparer les données pour le ML
Titre 2 : Sélectionnez et interrogez
Texte de description : sélectionnez et interrogez des données à partir de diverses sources de données telles que Amazon S3, Athena, Amazon EMR, Amazon Redshift, Snowflake, Databricks et plus de 50 autres sources tierces
Sous-description : importez des données à partir d'un magasin de fonctionnalités tel que Amazon SageMaker Feature Store
Titre 3 : nettoyez et enrichissez
Texte de description : nettoyez et explorez les données, procédez à l'ingénierie des fonctionnalités avec les transformations de données intégrées et détectez les biais statistiques avec SageMaker Clarify
Titre 4 : visualisez
Texte de description : assimilez graphiquement les données, détectez les valeurs aberrantes grâce à des modèles de visualisation préconfigurés et évaluez la qualité des données grâce à des rapports intégrés
Titre 5 : assimilez
Texte de description : utilisez un jeu de données échantillon pour estimer rapidement les performances et la précision du modèle, ainsi que pour diagnostiquer les problèmes potentiels
Titre 6 : opérationnalisez
Texte de description : lancez des tâches de traitement SageMaker ou des expériences SageMaker Autopilot, déployez le flux SageMaker Data Wrangler vers des points de terminaison SageMaker ou exportez-les sous forme de bloc-notes.
Accéder, sélectionner et interroger les données plus rapidement
Avec SageMaker Data Wrangler, vous pouvez accéder rapidement à des données tabulaires, textuelles et imagées à partir de services Amazon tels que S3, Athena, Redshift et de plus de 50 sources tierces. Vous pouvez sélectionner des données à l’aide du générateur de requêtes visuel, écrire des requêtes SQL ou importer des données directement dans différents formats tels que CSV et Parquet.

Générer des informations sur les données et comprendre la qualité des données
SageMaker Data Wrangler fournit un rapport sur la qualité et les perspectives des données qui vérifie automatiquement la qualité des données (telles que les valeurs manquantes, les lignes en double et les types de données) et aide à détecter les anomalies (telles que les valeurs aberrantes, le déséquilibre des classes et les fuites de données) dans vos données. Une fois que vous pouvez vérifier efficacement la qualité des données, vous pouvez rapidement appliquer des connaissances spécialisées pour traiter les jeux de données à des fins d'entraînement de modèles ML.

Comprendre vos données grâce à des visualisations
SageMaker Data Wrangler vous aide à comprendre vos données grâce à de robustes modèles de visualisation intégrés tels que des histogrammes, des diagrammes de dispersion, l’importance des fonctionnalités et des corrélations. Accélérez l’exploration des données grâce à des rapports intuitifs sur la qualité des données qui détectent les anomalies dans tous les types de données et fournissent des recommandations pour améliorer la qualité des données.

Transformer les données plus efficacement
SageMaker Data Wrangler propose plus de 300 transformations PySpark prédéfinies et une interface en langage naturel pour préparer des données sous forme de tableaux, de séries chronologiques, de texte et d’image sans codage. Les cas d’utilisation courants tels que la vectorisation de texte, la fonctionnalité de la date/heure, l’encodage, l’équilibrage des données ou l’augmentation de l’image sont couverts. Vous pouvez également créer des transformations personnalisées dans PySpark, SQL et Pandas ou utiliser une interface en langage naturel pour générer du code. Une bibliothèque intégrée d’extraits de code simplifie l’écriture de transformations personnalisées.

Comprendre le pouvoir prédictif de vos données
SageMaker Data Wrangler fournit une analyse de modèle rapide pour estimer le pouvoir prédictif de vos données. Vous obtenez une estimation de la précision du modèle, de l’importance des fonctionnalités et une matrice de confusion pour vous aider à valider la qualité de vos données avant d’entraîner des modèles.

Automatiser et déployer des flux de préparation de données ML
SageMaker Data Wrangler vous permet de mettre à l’échelle pour préparer des pétaoctets de données sans coder PySpark ni créer de clusters. Lancez des tâches de traitement directement depuis l’interface utilisateur ou intégrez la préparation des données dans les flux de travail de machine learning en exportant les données vers SageMaker Feature Store ou en les intégrant à SageMaker Pipelines. Vous pouvez également exporter des flux de données sous forme de blocs-notes Jupyter ou de script Python pour la réplication programmatique de vos étapes de préparation des données.

Clients
« Chez INVISTA, nous sommes axés sur la transformation et nous souhaitons développer des produits et des technologies qui aident nos clients dans le monde entier. Nous considérons le ML comme un moyen d'améliorer l'expérience client. Cependant, avec des jeux de données qui couvrent des centaines de millions de lignes, nous avions besoin d'une solution pour nous aider à préparer les données et à développer, déployer et gérer des modèles de ML à grande échelle. Avec Amazon SageMaker Data Wrangler, nous pouvons désormais sélectionner, nettoyer, explorer et comprendre efficacement nos données de manière interactive, ce qui permet à notre équipe de science des données de créer des pipelines d'ingénierie des fonctionnalités pouvant s'adapter sans effort à des jeux de données couvrant des centaines de millions de lignes. Avec Amazon SageMaker Data Wrangler, nous pouvons rendre opérationnels nos flux de travail de machine learning plus rapidement. »
Caleb Wilkinson, ancien responsable scientifique des données, INVISTA
« Avec le ML, 3M améliore les produits essayés et testés, comme le papier de verre, et encourage l'innovation dans plusieurs autres domaines, tels que celui de la santé. Alors que nous planifions d'instaurer le ML dans d'autres secteurs de 3M, nous voyons la quantité de données et de modèles augmenter rapidement, doublant chaque année. Nous avons hâte de découvrir les nouvelles fonctionnalités SageMaker parce que nous savons qu'elles nous aideront à nous mettre à l'échelle. Amazon SageMaker Data Wrangler simplifie la préparation des données destinées aux modèles d'entraînement et Amazon SageMaker Feature Store éliminera le besoin de créer encore et toujours les mêmes fonctionnalités de modèle. Enfin, Amazon SageMaker Pipelines nous aidera à automatiser la préparation de données, la création de modèles et le déploiement des modèles dans un flux de travail complet pour que la commercialisation de nos modèles se fasse plus rapidement. Chez 3M, nos chercheurs attendent avec impatience de pouvoir profiter de la nouvelle rapidité de la science. »
David Frazee, ancien directeur technique, 3M Corporate Systems Research Lab
« Amazon SageMaker Data Wrangler nous permet de partir sur les chapeaux de roues pour répondre à nos besoins en préparation de données avec une vaste collection d'outils de transformation qui accélèrent le processus de préparation de données pour le ML afin de commercialiser de nouveaux produits. Nos clients, à leur tour, profitent de ce moyen que nous utilisons pour mettre à l'échelle des modèles déployés qui nous permet de leur fournir des résultats mesurables et durables qui répondent à leurs besoins en seulement quelques jours et non plus quelques mois. »
Frank Farrall, Principal, Responsable écosystèmes et plateformes d'IA, Deloitte
« En tant que partenaire consultant AWS Premier, nos équipes d'ingénieurs travaillent en étroite collaboration avec AWS afin d'élaborer des solutions innovantes pour aider nos clients à améliorer constamment l'efficacité de leurs opérations. Le ML est au cœur de nos solutions innovantes, mais notre flux de travail de préparation des données implique des techniques de préparation des données sophistiquées qui, par conséquent, prennent beaucoup de temps avant de devenir opérationnelles dans un environnement de production. Avec Amazon SageMaker Data Wrangler, nos scientifiques des données peuvent mener à bien chaque étape du flux de travail de préparation des données, y compris la sélection, le nettoyage, l'exploration et la visualisation des données, ce qui nous aide à accélérer le processus de préparation des données et à préparer sans difficulté nos données pour le ML. Amazon SageMaker Data Wrangler nous permet de préparer plus rapidement des données pour le ML. »
Shigekazu Ohmoto, Directeur général principal de la société, NRI Japon
« Notre empreinte dans le marché de la gestion de la santé de la population continuait de se développer auprès de plus de régimes de soins de santé, de fournisseurs, de responsables des bénéfices en pharmacie et d'autres organisations de soins de santé. Nous avions donc besoin d'une solution permettant d'automatiser les processus de bout en bout pour les sources de données qui alimentent nos modèles de ML, dont les données de demandes, les données d'inscription et les données pharmaceutiques. Avec Amazon SageMaker Data Wrangler, nous pouvons désormais réduire le temps nécessaire au rassemblement et à la préparation des données pour le ML en utilisant un ensemble de flux de travail plus faciles à valider à et réutiliser. Cela a considérablement amélioré le temps de livraison et la qualité de nos modèles, augmenté l'efficacité de nos scientifiques des données et réduit le temps de préparation des données de quasiment 50 %. De plus, SageMaker Data Wrangler nous a permis d'éviter de nombreuses itérations de ML et de réduire significativement le temps requis pour le GPU. Le processus complet est maintenant plus rapide pour nos clients car nous pouvons créer des data marts avec des milliers de fonctions incluant le pharmaceutique, les codes de diagnostic, les visites chez le généraliste, les hospitalisations, ainsi que la démographie et d'autres déterminants sociaux. Avec SageMaker Data Wrangler, nous pouvons transformer nos données plus efficacement afin de créer des ensembles de données d'entraînement, de générer des informations sur les données des jeux de données avant d'exécuter les modèles de ML, et de préparer des données réelles du monde tel qu'il est pour une inférence/des prédictions à l'échelle. »
Lucas Merrow, PDG, Equilibrium Point IoT
Démarrer avec SageMaker Data Wrangler
Blogs
Vidéos
AWS re:Invent 2023 : Démocratiser le machine learning sans code ou avec peu de code à l’aide d’Amazon SageMaker Canvas (AIM217)
AWS re:Invent 2023 : Nouvelles fonctionnalités de LLM dans Amazon SageMaker Canvas, avec Bain & Company (AIM363)
Nouveautés
- Date (de la plus récente à la plus ancienne)