Qu’est-ce que l’entraînement de modèle SageMaker ?
L'entraînement de modèles Amazon SageMaker réduit le temps et les coûts d'entraînement et d'ajustement des modèles de machine learning (ML) à l'échelle sans que vous ayez à gérer l'infrastructure. Vous pouvez tirer parti de l’infrastructure de calcul de ML la plus performante actuellement disponible, et Amazon SageMaker AI peut automatiquement augmenter ou diminuer l’infrastructure, d’un à des milliers de GPU. Pour entraîner plus rapidement les modèles de deep learning, SageMaker AI vous aide à sélectionner et à affiner les jeux de données en temps réel. Les bibliothèques d’entraînement distribuées de SageMaker peuvent automatiquement répartir les modèles et les jeux de données d’entraînement volumineux entre les instances de GPU AWS, ou vous pouvez utiliser des bibliothèques tierces, telles que DeepSpeed, Horovod ou Megatron. Entraînez des modèles de fondation (FM) pendant des semaines et des mois sans interruption grâce à la surveillance et à la réparation automatiques des clusters d’entraînement.
Les avantages d'une formation économique
Entraîner des modèles à grande échelle
Tâches d’entraînement entièrement gérées
Les offres de tâches d’entraînement SageMaker offrent une expérience utilisateur entièrement gérée pour l’entraînement de FM distribués à grande échelle, éliminant ainsi les tâches indifférenciées liées à la gestion de l’infrastructure. Les tâches d’entraînement de SageMaker génèrent automatiquement un cluster d’entraînement distribué et résilient, surveillent l’infrastructure et se rétablissent automatiquement des erreurs pour garantir une expérience d’entraînement fluide. Une fois l’entraînement terminé, SageMaker désactive le cluster et le temps d’entraînement net vous est facturé. En outre, avec les tâches d’entraînement SageMaker, vous avez la possibilité de choisir le type d’instance le mieux adapté à une charge de travail individuelle (par exemple, préformer un LLM sur un cluster P5 ou affiner un grand modèle de langage (LLM) open source sur des instances p4d) afin d’optimiser davantage votre budget d’entraînement. En outre, les tâches de formation SageMaker offrent une expérience utilisateur cohérente à toutes les équipes de ML avec différents niveaux d’expertise technique et différents types de charge de travail.
SageMaker HyperPod
Amazon SageMaker HyperPod est une infrastructure spécialement conçue pour gérer efficacement les clusters de calcul afin de mettre à l’échelle le développement de modèles de fondation (FM). Il permet des techniques avancées d’entraînement des modèles, le contrôle de l’infrastructure, l’optimisation des performances et une meilleure observabilité des modèles. SageMaker HyperPod est préconfiguré avec les bibliothèques d’entraînement distribuées SageMaker, ce qui vous permet de répartir automatiquement les modèles et les jeux de données d’apprentissage sur les instances de cluster AWS pour aider à utiliser efficacement l’infrastructure de calcul et de réseau du cluster. Il offre un environnement plus résilient en détectant, diagnostiquant et en se rétablissant automatiquement des défaillances matérielles, ce qui vous permet d’entraîner les FM pendant des mois sans interruption, réduisant ainsi le temps d’entraînement jusqu’à 40 %.
Entraînement distribué haute performance
SageMaker AI accélère l’exécution d’entraînements distribués en répartissant automatiquement vos modèles et vos jeux de données d’entraînement entre les accélérateurs AWS. Il vous aide à optimiser votre tâche de formation à l’infrastructure réseau AWS et à la topologie des clusters. Il rationalise également le pointage des modèles via les recettes en optimisant la fréquence de l’enregistrement des points de contrôle, pour ainsi garantir un minimum de frais pendant la formation. Grâce aux recettes, les scientifiques des données et les développeurs de tous niveaux bénéficient de performances de pointe tout en commençant rapidement à entraîner et à optimiser des modèles d’IA générative accessibles au public, notamment Llama 3.1 405B, Mixtral 8x22B et Mistral 7B. Les recettes incluent une pile de formation qui a été testée par AWS, éliminant ainsi des semaines de travail fastidieux à tester différentes configurations de modèles. Vous pouvez basculer entre les instances basées sur GPU et les instances basées sur AWS Trainium en modifiant la recette en une seule ligne et activer le point de contrôle automatique des modèles pour améliorer la résilience de l’entraînement. En outre, vous pouvez exécuter des charges de travail en production sur la fonctionnalité d’entraînement SageMaker de votre choix.
Outils intégrés pour une précision maximale au moindre coût
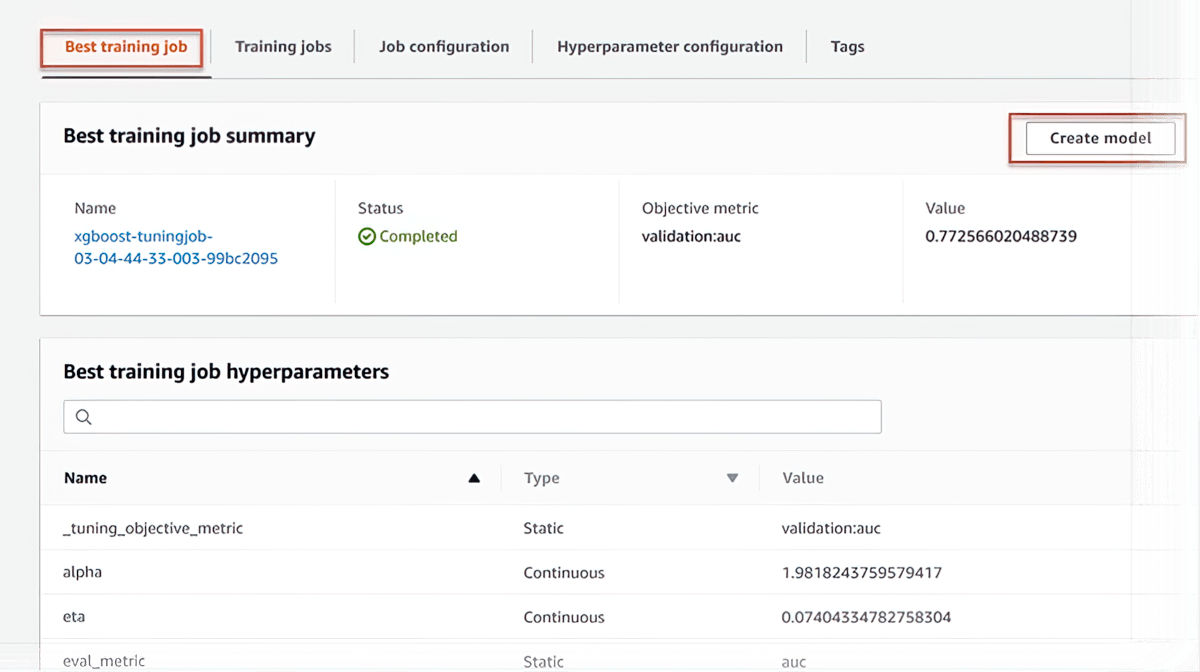
Ajustement automatique de modèle
SageMaker AI peut configurer automatiquement votre modèle en ajustant des milliers de combinaisons de paramètres d’algorithmes afin d’obtenir les prévisions les plus précises possible, vous économisant ainsi des semaines d’efforts. Il vous aide à trouver la meilleure version d'un modèle en exécutant de nombreuses tâches d'entraînement sur votre jeu de données.
Entraînement Spot géré
SageMaker AI contribue à réduire les coûts d’entraînement jusqu’à 90 % en exécutant automatiquement les tâches d’entraînement lorsque la capacité de calcul devient disponible. Ces tâches d'entraînement résistent également aux interruptions causées par des changements de capacité.
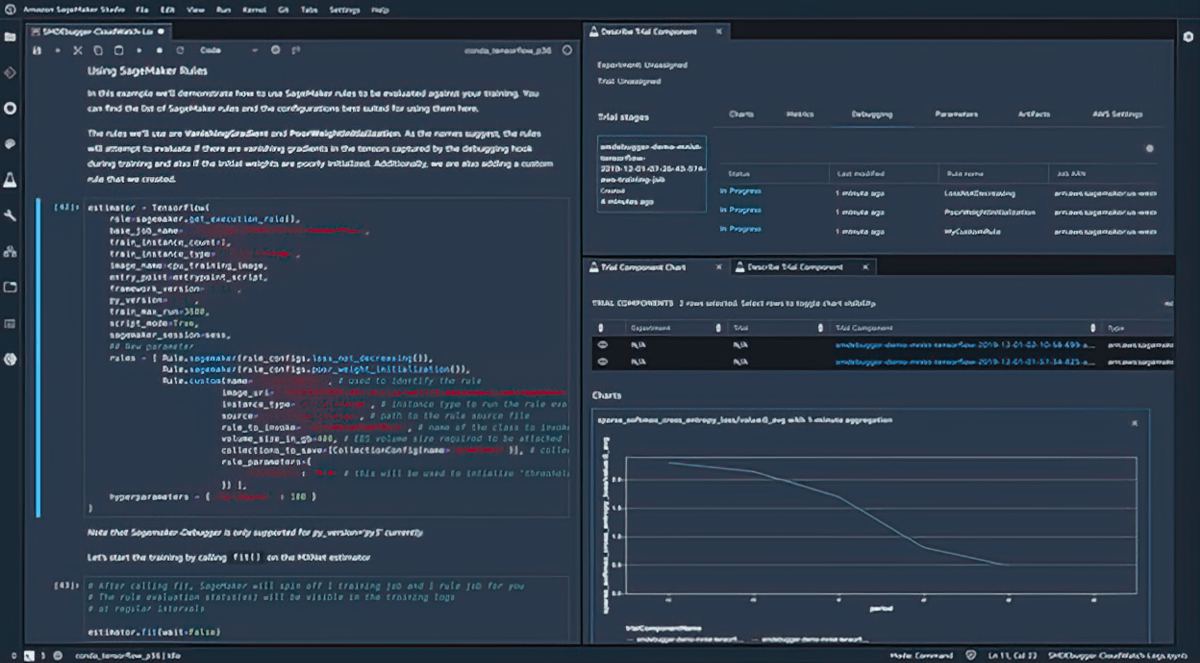
Débogage
Amazon SageMaker Debugger capture les métriques et profile les emplois de formation en temps réel afin que vous puissiez corriger rapidement les problèmes de performance avant de déployer le modèle en production. Vous pouvez également vous connecter à distance à l'environnement d'entraînement de modèles dans SageMaker pour le débogage et accéder au conteneur d'entraînement sous-jacent.
Profileur
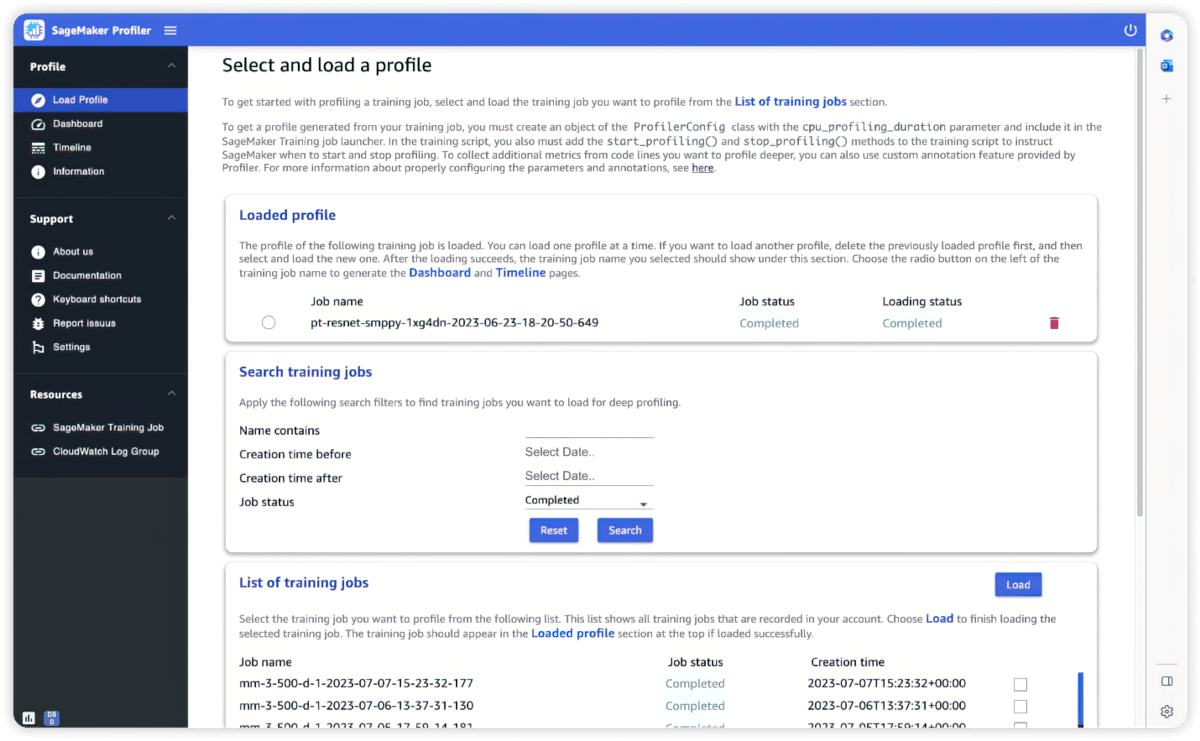
Outils intégrés pour l'interactivité et la surveillance
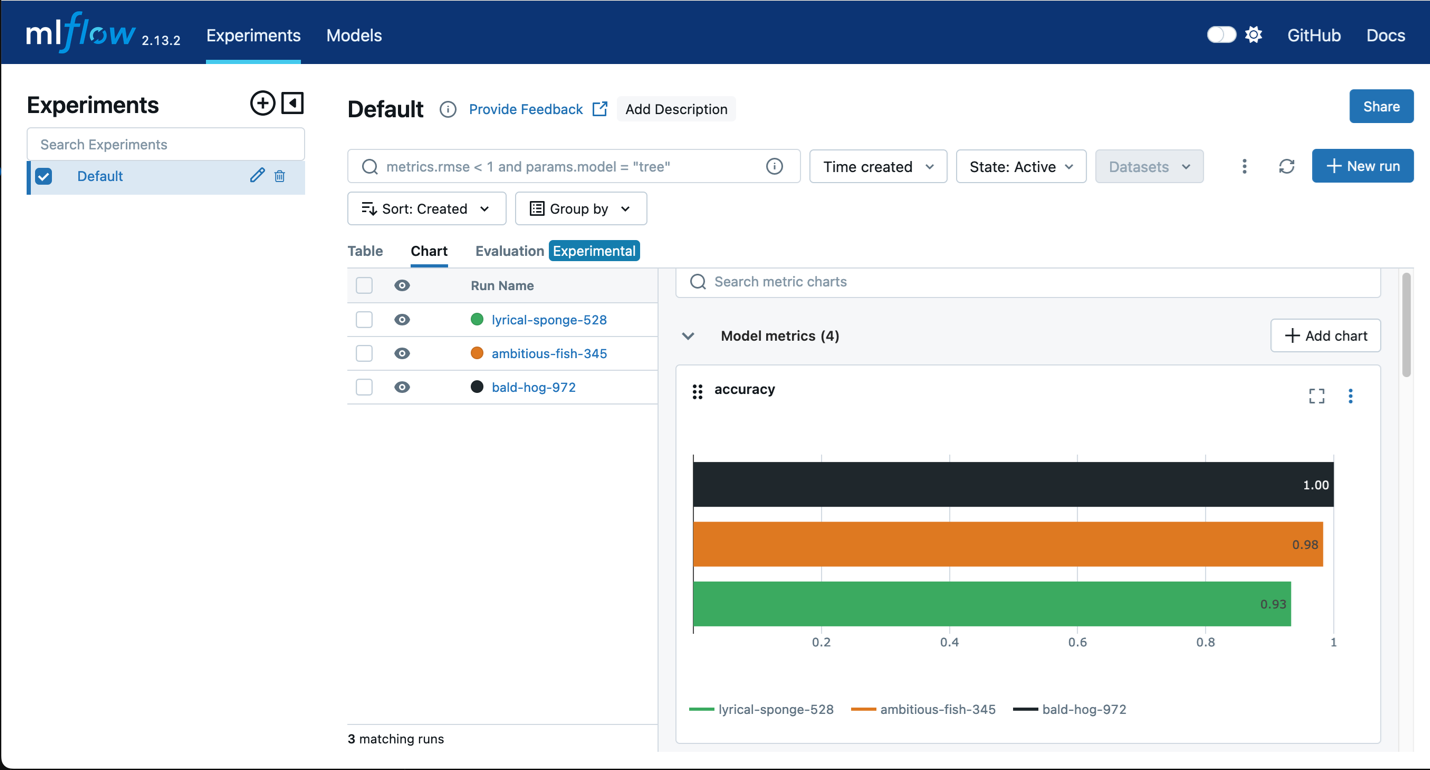
Amazon SageMaker avec MLflow
Utilisez MLflow avec l'entraînement SageMaker pour capturer les paramètres d'entrée, les configurations et les résultats, ce qui vous permet d'identifier rapidement les modèles les plus performants pour votre cas d'utilisation. L'interface utilisateur MLflow vous permet d'analyser les tentatives d'entraînement des modèles et d'enregistrer facilement les modèles candidats pour la production en une seule étape rapide.
Amazon SageMaker avec TensorBoard
Amazon SageMaker avec TensorBoard vous aide à gagner du temps de développement en visualisant l'architecture du modèle afin d'identifier et de résoudre les problèmes de convergence, tels que la perte de validation, l'absence de convergence ou la disparition de gradients.
Entraînement flexible et plus rapide
Personnalisation complète
SageMaker AI est fourni avec des bibliothèques et des outils intégrés qui facilitent et accélèrent l’entraînement des modèles. SageMaker AI fonctionne avec des modèles de ML open source très demandés tels que GPT, BERT et DALL·E, des cadres de ML, tels que PyTorch et TensorFlow, ainsi que des transformeurs, tels que Hugging Face. Avec SageMaker AI, vous pouvez utiliser des bibliothèques et des outils open source très demandés, tels que DeepSpeed, Megatron, Horovod, Ray Tune et TensorBoard, en fonction de vos besoins.
Conversion en code local
Amazon SageMaker Python SDK vous aide à exécuter le code ML local créé dans votre environnement de développement intégré (IDE) préféré et leurs blocs-notes locaux, ainsi que les dépendances d'exécution associées, sous forme de tâches d'entraînement de modèles de ML à grande échelle avec un minimum de modifications de code. Il vous suffit d'ajouter une ligne de code (décorateur Python) à votre code de ML local. SageMaker Python SDK utilise le code ainsi que les jeux de données et la configuration de l’environnement de l’espace de travail et l’exécute en tant que tâche d’entraînement SageMaker.
Flux d'entraînement de ML automatisés
L'automatisation des flux d'entraînement à l'aide d'Amazon SageMaker Pipelines vous aide à créer un processus reproductible afin d'orchestrer les étapes de développement du modèle pour une expérimentation rapide et une nouvelle formation du modèle. Vous pouvez exécuter automatiquement des étapes à intervalles réguliers ou lorsque certains événements sont initiés, ou vous pouvez les exécuter manuellement selon vos besoins.
Plans de formation flexibles
Pour respecter vos délais et vos budgets de formation, SageMaker AI vous aide à créer les plans d’entraînement les plus rentables qui utilisent les ressources de calcul provenant de plusieurs blocs de capacité de calcul. Une fois que vous avez approuvé les plans d’entraînement, SageMaker AI alloue automatiquement l’infrastructure et exécute les tâches de formation sur ces ressources informatiques sans aucune intervention manuelle, ce qui vous permet de gagner des semaines à gérer le processus d’entraînement afin d’aligner les tâches sur la disponibilité des ressources de calcul.
Ressources
Nouveautés
- Date (de la plus récente à la plus ancienne)